# GoLang 学习笔记
# 1.Go(package)
# 1. 标准库概述
像 fmt, os 等具有常用功能的内置包被称为标准库,大部分内置于 Go 本身
unsafe: 包含一些打破 GO 语言 "类型安全" 的命令,一般程序中不回使用,可用在 C/C++ 程序的调用中syscall - os - os/exec :os: 提供平台无关性的擦偶作系统功能接口,采用 Unix 设计,隐藏了不同操作系统间的差异,让不同的文件系统和操作系统对象表现一致
os/exec: 提供运行外部操作系统命令和程序的方式syscall: 底层的外部包,提供操作系统底层调用的基本接口
archive/tar和/zip-commpress: 压缩 (解压缩) 文件fmt-io-bufio-path/filepath-flag:fmt: 提供格式化输入输出功能.io: 提供了基本输入输出功能,大多数是围绕系统功能的封装bufio: 缓冲输入输出功能的封装path/filepath: 用来操作当前系统中的目标文件名路径flag: 对命令行参数的操作
strings - strconv - unicode - regexp - bytes:strings: 提供对字符串的操作strconv: 提供将字符串转为基础类型的功能unicode: 为 Unicode 类型的字符串提供特殊的功能regexp: 正则表达式功能bytes: 提供对字符串分片的操作index/suffixarray: 字符串快速查询
math - math/cmath - math/big - math/rand - sort:math: 基本数学函数math/cmath: 对复数的操作math/rand: 伪随机数生成sort: 数组,自定义集合排序math/big: 大数字的实现和计算
container - /list-ring-heap: 集合操作list: 双链表right: 环形链表
time-logtime: 日期和时间的基本操作.log: 记录程序运行时产生的日志
encoding/json - encoding/xml - text/template:encoding/json: 读取并解码 写入并编码 JSON 数据encoding/xml: 简单的 XML1.0 解析器text/template: 生成像 HTML 一样的数据与文本混合的驱动模板
net - net/http - html:net: 网络数据的基本操作http: 提供一个可拓展的 HTTP 服务器和基础客户端,解析 HTTP 请求和回复html: HTML5 解析器
runtime: Go 程序运行时的交互操作,例如垃圾回收和携程创建reflect: 实现通过程序运行时反射,让程序操作任意类型的变量exp: 包中有许多将被编译为新包的实验性包.
# 2.regexp 包
简单模式,使用
Match方法,变量 ok 将返回 true 或者 falseok, _ := regexp.Match(pat,[]byte(searchIn))使用
MatchString, 直接传入字符串ok, _ := regexp.MatchString(pat, searchIn)Compile函数肯返回一个错误,一般使用时忽略对错误的判断,NustCompile一样可以检验正则的有效性,当正则不合法时,程序将panic
# 3. 锁和 sync 包
复杂程序中,通常通过不同线程执行不同应用来实现程序的并发,导致不同线程对同一变量
使用的竞争 (通常被称为资源竞争)
map 类型不存在锁机制来实现安全访问的效果 (出于对性能的考虑),map 类型是非线程安全的,
并行访问共享的 map 类型数据时,map 数据将会出错
Go 语言的锁机制时通过 sync 包中的 Mutex 来实现的,sync 来源于 synchronize, 表示线程
将有序的对同一变量进行访问
sync.Mutex是一个互斥锁,其作用是守护领截取入口,确保同一时间只能有一个线程进入临界区
sync 包中还有
RWMutex锁:通过RLock()允许同一时间多个线程对变量进行读操作,但只能一个线程进行写操作,如果使用
Lock()将和普通的Mutex作用相同, 包中还有 once.Do(call)这个方法确保被调用函数只能被调用一次
sync 可以解决同一时间只能一个线程访问 map 类型数据的问题,但会导致程序明显变慢或引起其他
问题,go 提倡使用
goroutines和channels来解决问题
import "sync" | |
type Infostruct{ | |
mu sync.Mutex | |
//···other fields,s1.s2.: Str string | |
} | |
func Update(info *Info){ | |
info.mu.Lock() | |
info.Str = //new value | |
info.mu.Unlock() | |
} |
# 4. 精密计算和 big 包
go 语言中的
float64类型进行浮点运算,返回结果精确到 15 位,但对超出int64或uint64类型的大数字进行计算时对精度要求严格,就无法使用浮点数,在内存中只能近似的表示
对于整数的高精度计算 GO 语言提供了
big包,包含在math包下,有用来表示大有理数的big.Rat类型和表示大整数的
big.Int类型,可以实现任意类型的数字,但内存消耗更大,处理起来也比内置的数字类型慢很多
大整型数字是通过
big.NewInt(n)来构造的,n 为int64类型整数.大有理数通过
big.NewRat(n,d)构造,n(分子) d(分母)都是int64类型整数大数字类型计算,Add (),Sub (),Mul (),Div () < 加,减,乘,除 >, 计算结果返回后可链式调用,无需中
间变量保存,节省内存
# 5. 自定义包和可见性
包时 Go 语言中代码组织和代码编译的主要方式.
自定义包命名要使用短小且不含有 _(下划线) 的小写单词来为文件命名
import alias "./pack"导入pack包,并取别名alias, 通过alias进行调用import . "./pack"使用.作为包的别名时,可以不通过包名来使用其中的项目例如:
test := ReturnStr()import _ "./pack1/pack1", 只导入其副作用,只执行它的 init 函数并初始化其中的全局变量导入外部安装包
go installgo mod使用时包引用需要以项目根路径开始
# 2. 结构体 (struct)
- Go 通过类型别名 (alias types) 和 结构体的形式支持用户自定义类型,一个带属性的结构体试图表示显示世界中的实体。结构体是复合类型 (composite types), 当需要定义一个类型,由一系列属性组成,就应该使用结构体,结构体将数据聚集在一起进行访问,就像是一个独立实体的一部分,结构体也是值类型,因此可以通过 new 函数来创建.
- 组成结构体类型的数据被称为字段,每个字段都有一个类型和名字,在结构体中, 字段名字必须是唯一的
- 结构体在软件工程上旧的术语是 ADT (抽象数据类型 Abstract Data Type), 在一些老的编程语言中称为记录 (Record), 在 c 家族中也存在,并且也是 struct, 在面向对象的变成语言中,类似于无方法的轻量级类,但 Go 语言没有类的概念,因此,Go 中结构体有着更为重要的地位.
- 结构体是值类型数据
# 1. 结构体定义
- 结构体定义的一般方式
type identifier struct { | |
field1 type1 | |
field2 type2 | |
... | |
} | |
// 定义简单的结构体 | |
typr T struct {a,b int} |
- 结构体的字段都有名字,如果字段在代码中从来不会被使用,那么也可以命名为 _(下划线).
- 结构体的字段可以是任何类型,甚至可以是结构体本身,也可以是函数或结构
- 数组可以看作是一种结构体类型,不过其使用的是下标不是具名的字段
- new 函数给一个新的结构体分配内存,返回指向已分配内存的指针:
var t *T = new(T), 如果需要可以将语句放在不同的行 (例如:定义是包范围的,但是却没必要立刻分配)
var t *T | |
t = new(T) | |
// 惯用语法,变量 t 是指向 T 的指针,此时结构体字段值为所属类型的零值 | |
t := new(T) | |
/** | |
* 声明 t 也会给 t 分配内存,并零值化内存,但此时 t 是类型 T, | |
* 在这两种方式中 t 被称为 类型 T 的 一个实例 (instance) 或 对象 (object) | |
*/ | |
var t T |
使用
fmt.Println打印一个结构体的默认输出可以很好的显示其内容,类似使用 % v 选项像面向对象的语言那样,结构体也可以使用点号符给字段赋值:
structname.fieldname = value使用点号符可以获取结构体的字段值: structname.filedname , 在 Go 语言中这叫做 ** 选择器 (selector)** 无论是 结构体类型 还是结构体类型指针,都使用同样的 ** 选择器符 (selector-notation)** 来引用结构体的字段
typr myStruct struct {i int} | |
var v myStruct //v 是结构体类型变量 | |
var p *myStruct //p 是指向一个结构体类型变量的指针 | |
v.i | |
p.i | |
// 初始化结构体实例的 更简短和惯用的方式如下: | |
ms := &struct1{10, 15.6, "Chris"} | |
// 混合字面量语法 (composite literal syntax) &struct {a, b, c} 是一种简写,底层仍会调用 new () |
初始化结构体实例的 更简短和惯用的方式如下:
ms := &struct1{10, 15.6, "Chris"}混合字面量语法 (composite literal syntax)
&struct{a, b, c}是一种简写,底层仍会调用
new(), 这里的值必须按照字段顺序来写,表达式new(Type)和&Type{}是等价的结构体的初始化方式
(A): 必须以字段在结构体定义时的顺序赋值,& 不是必须的
(B): fieldname (字段名) : val (值), 这种形式顺序不必一直
(C): fieldname : val 形式赋值可以进行部分赋值
typr Interval struct { | |
start int | |
end int | |
} | |
// 初始化方式 | |
方式(A): intr := Interval{0 ,3} | |
方式(B): intr := Interval{end: 5,start: 1} | |
方式(C): intr := Interval{end: 5} |
结构体初始化
- 结构体声明时,其值类型字段默认为相关类型的空值
- 其引用数据类型默认为 nil, 使用 slice, map 等引用类型时,需要先 make 再使用
- 不同结构体字段时独立的,互不影响
使用 new 初始化
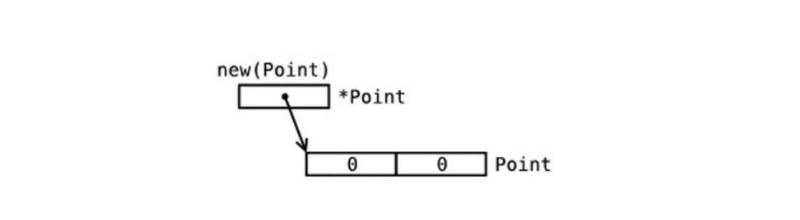
作为结构体字面量初始化
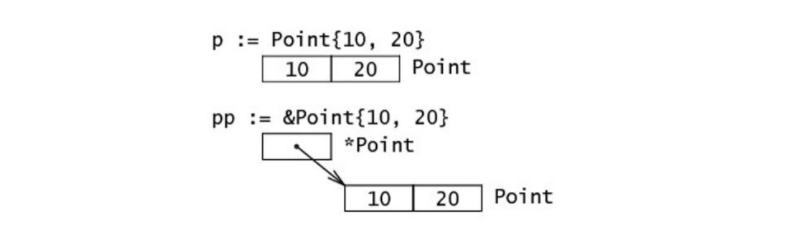
struct 初始化及调用的不同方式
type Personstruct { | |
firstName string | |
lastName string | |
} | |
func upPerson(p *Person) { | |
p.firstName = strings.ToUpper(p.firstName) | |
p.lastName = strings.ToUpper(p.lastName) | |
} | |
func main() { | |
// 1-struct as a value type: | |
var pers1 Person | |
pers1.firstName = "Chris" | |
Pers1.lastName = "Woodward" | |
upPerson(&pers1) | |
fmt.Printf("The name of the person is %s %s\n",pers1.firstName,pers1.lastName) | |
// 2-struct as a pointer | |
pers2 := new(Person) | |
/** | |
* 通过 new 出来的指针,也可以直接使用 | |
* . 点语法进行字段赋值 | |
* GO 语言会自动进行转换 | |
*/ | |
pers2.firstName = "Chris" | |
pers2.lastName = "Woodward" | |
// 通过解指针的方式来设置值 | |
(*pers2).lastName = "Woodward" | |
upPerson(pers2) | |
fmt.Printf("The name of the person is %s %s\n",pers1.firstName,pers1.lastName) | |
// 3-struct as a literal: | |
pers3 := &Person{"Chris","Woodward"} | |
upPerson(per3) | |
fmt.Printf("The name of the person is %s %s\n",pers1.firstName,pers1.lastName) | |
// 4-struct as a literal: | |
pers3 := &Person{firstName: "Chris",lastName: "Woodward"} | |
upPerson(per3) | |
fmt.Printf("The name of the person is %s %s\n",pers1.firstName,pers1.lastName) | |
} |
结构体的内存布局
Go 语言中,结构体和其所包含的数据类型在内存中是以连续块的形式存在的,(即使结构体中嵌套有其他的结构体)
type Rect1struct{Min,MaxPoint} | |
type Rect2struct{Min,Max*Point} |
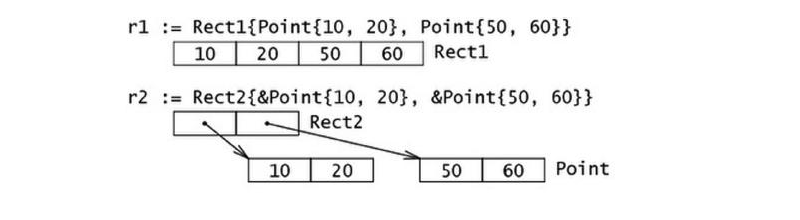
递归结构体:链表

/** | |
* 链表的第一个元素为 head, 其指向第二个元素, | |
* 最后一个元素 tail 没有后继元素,所以 su 为 nil | |
* 链表存在很多数据节点,且可以动态增长或收缩 | |
*/ | |
type Nodestruct{ | |
data float64 | |
su *Node | |
} | |
// 双向链表,由前趋节点 pr 和 后继节点 su : | |
type Nodestruct{ | |
pr *Node | |
data float64 | |
su *Node | |
} |
递归结构体:二叉树
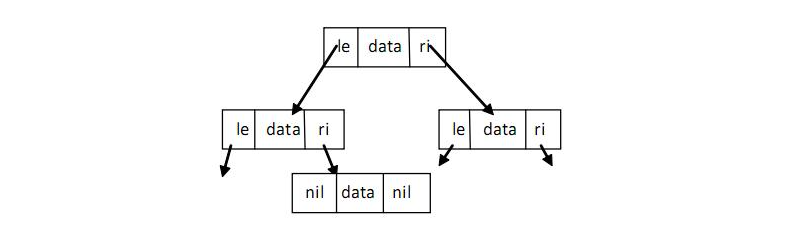
/** | |
* 二叉树每个节点 至多链接至两个节点: | |
* 左节点 (le) 右节点 (ri) | |
* 左右节点本身也可以有左右节点 | |
* 树的顶层节点:根节点 (root) | |
* 叶子节点 (leaves), 叶子节点的 le 和 ri 指针为 nil | |
*/ | |
type Treestruct { | |
le *Tree | |
data float64 | |
ri *Tree | |
} |
结构体转换
Go 类型转换遵循严格的规则,当结构体定义了一个 alias (别名) 类型时,结构体 和 其 alias 类型都有相同的底层类型,两者可以互相转换,但须注意其中非法复制或转换引起的编译错误
type number struct { | |
f float32 | |
} | |
type nr number //alias type | |
func main() { | |
a := number{5.0} | |
b := nr{5.0} | |
// var i float32 = b | |
// compile-error: cannot use b (type nr) as type float32 in assignment | |
// var i = float32(b) | |
// compile-error: cannot convert b (type nr) to type float32 | |
// var c number = b | |
// compile-error: cannot use b (type nr) as type number in assignment | |
// needs a conversion: | |
var c = number(b) | |
fmt.Println(a, b, c) | |
} |
# 2. 结构体工厂
- Go 语言不支持面向对象编程语言中的构造方法,但可以很容易的在 Go 中实现 =="构造工厂"== 方法.
通常会为类型定义一个工厂,工厂名字以 new 或 New 开头
type File struct { | |
fd int // 文件描述符 | |
name string // 文件名 | |
} | |
// 结构体类型对应的工厂方法,返回一个指向结构体实例的指针 | |
func NewFile(fd int, name string) *File { | |
if fd < 0 { | |
return nil | |
} | |
return &File{fd, name} | |
} | |
// 调用工厂方法,返回实例化对象 | |
f := NewFile(10,"./test.txt") |
- 结构体类型 初始化表达式
new(File)和&File{}是等价的 - 获取 结构体类型 T 的一个实例占用内存,size := unsafe.Sizeof (T {})
- 强制使用工厂方法:结构体名称首字母小写变为私有
type matrix struct { | |
... | |
} | |
func NewMatrix(params) *matrix { | |
m := new(matrix) // 初始化 m | |
return m | |
} | |
// 在其他包中使用工厂 | |
package main | |
import "matrix" | |
... | |
wrong := new(matrix.matrix) // 编译失败(matrix 是私有的) | |
right := matrix.NewMatrix(...) // 实例化 matrix 的唯一方式 |
map 和 struct vs new () 和 make ()
能够使用
make()的三种类型 : slice\maps\channelsmake()一个结构体变量,会引发编译错误new()一个 map 向其填充数据会引发运行时错误,new(slice)返回的是指向nil的指针其尚未被分配内存,所以在使用 map 是需要谨慎
# 3. 使用自定义包的结构体
在 main.go 中使用来自 struct_pack 下的包 structPack
// structPack.go | |
package structPack | |
type ExpStruct struct { | |
Mi1 int | |
Mf1 int | |
} | |
// main.go | |
package main | |
import ( | |
"fmt" | |
"./struct/pack/structpack" | |
) | |
func main() { | |
struct := new(structPack.ExpStruct) | |
struct.Mi1 = 10 | |
struct.Mf1 = 16 | |
fmt.Printf("Mi1 = %d\n", struct1.Mi1) | |
fmt.Printf("Mf1 = %f\n", struct1.Mf1) | |
} | |
// 输出 | |
Mi1 = 10 | |
Mf1 = 16.000000 |
# 4. 带标签的结构体
结构体中的字段除了有名字和类型外,还有一个可选的
标签(tag): 是一个附属于字段的字符串,可以是文档或其他的重要标记,标记内容不可以在一般的变成中使用,只有 包reflect能获取reflect可以在 运行时自省类型,屬性和方法,使用reflect.TypeOf(variable)获取变量的正确类型,reflect.TypeOf(struct)可以通过返回值的Field来索引结构体的字段,然后使用其 Tag 属性
package main | |
import ( | |
"fmt" | |
"reflect" | |
) | |
type TagType struct { // tags | |
//json db 格式化使用形式 `json:"name"db:"name"` | |
field1 bool "An important answer" | |
field2 string "The name of the thing" | |
field3 int "How much there are" | |
} | |
//json 序列化时使用 tag | |
type TagType struct { // tags | |
field1 bool "An important answer" | |
field2 string "The name of the thing" | |
field3 int "How much there are" | |
} | |
func main() { | |
tt := TagType{true, "Barak Obama", 1} | |
for i := 0; i < 3; i++ { | |
refTag(tt, i) | |
} | |
} | |
func refTag(tt TagType, ix int) { | |
ttType := reflect.TypeOf(tt) | |
ixField := ttType.Field(ix) | |
fmt.Printf("%v\n", ixField.Tag) | |
} | |
// 输出 | |
An important answer | |
The name of the thing | |
How much there are |
# 5. 匿名字段和内嵌结构
- 结构体可以包含一个或多个匿名 (或内嵌字段), 即字段没有显示的名字,只有字段类型是必须的,此时类型就是字段的名字。匿名字段本身可以是一个结构体类型,即 结构体可以包含内嵌结构体
- Go 语言中 通过内嵌或组合实现 模拟类的继承行为,Go 语言中,相比较继承,组合更受青睐
- 通过类型
outer.int的名字来获取存储在匿名字段中的数据,因此 (在一个结构体中每一种数据类型只能有一个匿名字段)
type innerS struct { | |
in1 int | |
in2 int | |
} | |
type outerS struct { | |
b int | |
c float32 | |
int // anonymous field | |
innerS //anonymous field | |
} | |
func main() { | |
outer := new(outerS) | |
outer.b = 6 | |
outer.c = 7.5 | |
outer.int = 60 | |
outer.in1 = 5 | |
outer.in2 = 10 | |
fmt.Printf("outer.b is: %d\n", outer.b) | |
fmt.Printf("outer.c is: %f\n", outer.c) | |
fmt.Printf("outer.int is: %d\n", outer.int) | |
fmt.Printf("outer.in1 is: %d\n", outer.in1) | |
fmt.Printf("outer.in2 is: %d\n", outer.in2) | |
// 使用结构体字面量 | |
outer2 := outerS{6, 7.5, 60, innerS{5, 10}} | |
fmt.Println("outer2 is:", outer2) | |
} |
内嵌结构体
- 结构体也是一种数据类型,因此也可以做为一个匿名字段来使用,外层结构体通过
outer.struct.File直接进入内层结构体的字段,内层结构体甚至可以来自其他包,内层结构体被简单的插入或者内嵌进外层结构体,这种 简单继承机制提供了一种方式,使得可以从另一个或者一些类型继承部分或全部实现
package main | |
import "fmt" | |
type A struct { | |
ax, ay int | |
} | |
type B struct { | |
A | |
bx, by float32 | |
} | |
func main() { | |
b := B{ A{1,2}, 3.0, 4.0} | |
fmt.Println(b.ax, b.ay, b.bx, b.by) | |
fmt.Println(b.A) | |
} | |
// 输出 | |
1 2 3 4 | |
{1,2} |
命名冲突 当两个字段拥有相同的名字 (可能是继承来的名字)
- 外层名字会覆盖内层名字 (但是两者的内存空间都保留), 这提供了一种重载字段或方法的方式;
- 如果相同的名字在同一级别出现两次,且这个名字被程序使用了,将会应发一个错误 (不使用则不影响), 没有办法解决这种问题引起的二义性
- 类型别名:处理 JSON 相关操作 type
strMap2Any = map[string]interface {}
/** | |
* 规则 2: 使用 c.a 是错误的,无法确定是 c.A.a 还是 c.B.a , 会导致编译器错误: | |
* ambiguous DOT reference c.a disambiguate with either c.A.a or c.B.a。 | |
*/ | |
type A struct{a int} | |
type B struct{a, b int} | |
type c struct {A; B} | |
func main { | |
var c C | |
//c.a = 11 ambiguous selector c.a 模棱两可的选择器 | |
c.A.a = 10 | |
c.B.a = 50 | |
c.B.b = 30 | |
fmt.Printf("%+v",c) | |
} | |
输出 : {A:{a:10} B:{a:50 b:30}} | |
/** | |
* 规则 1: 使用 d.b 是没问题的:获取的是 float32, 而不是 B 的 b | |
* 想要内层的 b 可以通过 d.B.b 得到 | |
*/ | |
type D struct {B; b float32} |
# 6. 结构体方法
- 在 Go 语言中,结构体就像是类的一种简化形式,Go 方法是作用在接受者 (receiver) 上的一个函数,接收者是某种类型的变量。因此方法是一种特殊类型的函数.
- 接收者类型 (几乎) 是任何类型,任何类型都可以有方法,甚至是函数类型,可以是 int、bool、string 或数组的别名类型,但 接收者不能是一个接口类型,因为接口是一个抽象定义,但是方法是具体实现.
- 接收者不能是一个指针类型,但是可以是任何其他允许类型的指针
- Go 语言中,类型的代码和绑定的方法可以 在不同源文件,但是必须是同一个包.
- 因为方法是函数,所以不允许方法重载,即 对于一个类型只能有一个给定名称的方法,但基于接收者类型,是有重载的:具有相同名字的方法可以再两个或者多个不通风的接收者类型上存在
// 别名类型 没有原始类型上已经定义过的方法 | |
func (a *denseMatrix) Add(b Matrix) Matrix | |
func (a *sparseMatrix) Add(b Matrix) Matrix |
# 1. 定义方法的一般格式 :
recv就像是面向对象语言中的this或self, Go 中并没有这两个关键字,可以使用this或self作为receiver的名字
// 在方法名之前,func 关键字之后的括号中指定 receiver | |
func (recv receiver_type) methodName(parameter_list) (return_value_list) { ... } | |
// 如果方法不需要使用 recv 的值,可以用 _替换 | |
func (_ recevier_type) methodName(parameter_lsit) (return_value_list) {...} | |
/** | |
* 如果 `recv` 是 `receiver` 的实例,`Method` 是方法名 | |
* 那么方法调用遵循传统的 `object.name` 选择器符号: | |
*/ | |
type Recevier struct{ | |
... | |
} | |
func (r recevier) Method(){ | |
... | |
} | |
var recv Recevier | |
recv.Method() |
# 2. 类型和对应方法的定义域
- 类型和作用在其上的方法必须在同一个包定义,类型在其他 或 非本地的包中定义方法都会报错
- 通过 定义类型的别名类型,然后再为别名类型定义方法。或将其 作为匿名类型嵌入在新的结构体中 (方法只在别名类型上有效)
// 别名类型定义方法 | |
type myTime time.Time | |
func (t myTime) cropTime() string { | |
return t.LocalTime().String()[0:3] | |
} | |
// 匿名嵌入结构体中 | |
type myTime struict { time.TIme /* 匿名字段 */} | |
func (t myTime) cropTime() string { | |
return t.LocalTime().String()[0:3] | |
} |
# 3. 函数和方法的区别
- 函数将变量作为参数:
Function (recv) - 方法在变量上被调用:
recv.Method() - 在接受者是指针时,方法可以改变接收者的值 (或状态), 函数将参数作为指针传递也可以做到
- 接收者必须有一个 显示的名字,这个名字必须在方法中被使用
receiver_type叫做 (接收者) 基本类型,这个类型必须在和方法同样的包中被声明- Go 中 (接收者) 类型关联的方法不必写在类型结构体中,耦合更加宽松;类型和方法之间的关联由接收者建立
- 方法 没有和 数据定义 (结构体) 混合在一起:两者是正交的类型;表示 ==(数据)== 和行为 (方法) 是独立的
# 4. 指针或值作为接收者
- 鉴于性能原因,
recv最常见的是一个指向receiver_type的指针 - 想要方法改变接收者的数据,就在接收者类型的指针上定义该方法,否则就在普通的值类型上定义方法
- Go 为我们做了探测工作,我们无需指出是否在指针上调用方法
- 指针方法和值方法都可以在指针或非指针上被调用
# 5. 方法和未导出字段
getter和setter, 对 导出类型Person的未导出字段进行赋值和获取- 对象的字段 (属性) 不应该由 2 个或 2 个以上的线程在同一时间改变,如果程序发生这种情况,为了安全并发访问,可以使用包
sync中的方法
package person | |
type Person struct { | |
field1 string | |
field2 string | |
} | |
func (p *Person) Field1() string { | |
return p.field1 | |
} | |
func (p *Person) SetField1(newName string) { | |
p.firstName = field1 | |
} |
# 6. 内嵌类型的方法和继承
- 当一个匿名类型被 内嵌在结构体中 时,匿名类型 的可见方法 也同样被内嵌,效果等同于 继承 了这些相关方法: 将父类型放在子类型中来实现亚型。这个机制提供了一种简单的方式来模拟经典面向对象语言中的子类和继承相关的效果
- 内嵌将已经存在类型的字段和方法注入到 另一个类型中:匿名字段上 的 方法 "晋升" 为外层类型的方法,类型也可以有只作用于本身实例而不作用于内嵌 "父类型" 的方法
- 覆写方法 (像字段一样) : 和内嵌方法具有相同名字的外层类型的方法会覆写内嵌类型对应的方法
- 因为一个结构体可以嵌入多个匿名类型,所以可以实现简单版本的 多重继承.
- 结构体内嵌 同包结构体时,可以彼此访问对方所有的字段和方法
# 7. 在类型中嵌入功能
- 聚合 (或组合): 包含一个所需功能类型的具名字段 (需要使用 field.func () 调用对应的聚合方法)
- 内嵌:内嵌 (匿名的) 所需功能类型 (可以直接使用匿名字段方法)
- 内嵌类型嵌入其他类型时,那些类型的方法也可以直接在外层类型中使用
# 8. 多重继承
- 多重继承:类型获得多个父类型行为的能力,Go 语言中,通过在类型中嵌入所必要的父类型,可以简单的实现多继承.
- 多重继承结构体使用
&struct{ field: "" }进行赋值时要么 全省略字段值,要么全使用字段值
type Base struct { | |
id string | |
} | |
func (b *Base) Id() string{ | |
return b.id | |
} | |
func (b *Base) SetId(id string) { | |
b.id = id | |
} | |
type Person struct { | |
Base | |
firstName string | |
lastName string | |
} | |
type Employee struct { | |
Person | |
salary float32 | |
} | |
func test02() { | |
// 全使用字段名进行对应赋值 | |
emp := &Employee{Person: Person{Base: Base{id:"101010"},firstName: "black",lastName:"cat"} ,salary: 36.5} | |
// 全省略字段名进行赋值 | |
emp := &Employee{Person{Base{"1001101"},"white","cat"},6600.5} | |
fmt.Printf("%+v\n",emp) | |
fmt.Printf("%+v\n",emp.id) | |
} |
# 9. 通用方法和方法命名
- 在编程中 一些基本操作会一遍遍重复出现,例如 == 打开(Open)、关闭(Close)、读(Read)、写(Write)、排序(Sort)== 等等,并且都有一个大致的意思。具体的实现可能前差万别,但是基本的概念是一致的.
- Go 语言中通过使用接口,标准库广泛的应用了这些规则,在标准库中这些方法都有一致的名字,如 Open(),Read(),write() 等.
- 书写规范的 Go 程序,就应该遵守这些约定,get 方法合适的名字和签名
# 10. Go 语言的方法和其他面向对象语言比较
- Go 语言中,类似其他语言的继承层次完全没必要,如果方法在此类型定义了,就可以调用,和其他类型上是否存在这个方法没有关系,因此 Go 在这方面具有更强大的灵活性
- Go 不需要一个显示的类定义,"类" 是通过提供一组作用于一个共同类型的方法集来隐式定义。类型可以是 结构体 或 任何用户自定义类型
- 在 Go 中,类型就是类 (数据和关联的方法). Go 没有类似面向对象语言的类继承概念,继承的两个好处:代码重复 和 多态.
- 在 Go 中,代码复用通过组合和委托实现,多态通过接口的使用来实现:有时候也称为 组件编程 (Component Programming)
- 相比于类继承,Go 的接口提供了更强大,更简单的多态行为
goop包,给 Go 提供了 JavaScript 风格的对象 (基于原型的对象), 并且支持多重继承和类型独立分派
# 7. 类型的 String 方法和格式化描述符
- 当定义了一个有很多方法的类型时,大概率会使用
String()方法来定制类型的字符串形式的输出 (一种可阅读性和打印性的输出). String()方法会被用在fmt.Printf()中生成默认的输出,等同于使用格式化描述符 % v 产生的输出,fmt.Print()和fmt.Println()也会自动使用String()方法- 在
String()方法中调用涉及String()方法的方法会导致无限递归,并很快导致内存溢出,例如 (在T.String()中调用fmt.Sprintf(), 但fmt.Printf()又会反过来调用T.String()...)
# 8. 垃圾回收和 SetFinalizer
- Go 开发者不需要写代码来释放程序中不再使用的变量和结构占用的内存
- Go 运行时有一个独立的进程,即垃圾收集器 (GC), 会处理,GC 进程搜索不在使用的变量然后释放其内存,可以通过
runtime包访问 GC 进程 - 通过调用
runtime.GC()函数可以显示的触发 GC, 但这些之爱子某些罕见的场景下才有用,比如 当内存资源不足时调用runtime.GC(), 它会在此函数执行的点上立即释放一大片内存,此时程序可能会短暂的性能下降 (因为 GC 进程在执行)
获取当前的内存状态
输出当前已分配内存的总量,单位是 KB
// fmt.Printf("%d\n", runtime.MemStats.Alloc/1024) | |
// 此处代码在 Go 1.5.1 下不再有效,更正为 | |
var m runtime.MemStats | |
runtime.ReadMemStats(&m) | |
fmt.Printf("%d Kb\n", m.Alloc / 1024) |
# 3. 接口 (Interface) 与反射 (Reflection)
# 1. 接口的定义
- Go 语言没有,类和继承的概念,但是有非常灵活的接口概念,通过接口可以实现很多面向对象的特性.
- 接口提供了一种方式来说明 对象的行为
- 接口的名字通常 由方法名加
[e]r后缀组成,例如: Printer,Reader,Writer; 当后缀 er 不合适时,如Recoverable, 接口以 able 结尾,或以I开头
接口定义:
type Namer interface { | |
Method1(param_list) return_type | |
Method2(param_list) return_type | |
} |
- Go 语言中接口可以有值,一个接口类型的变量 或 一个接口值:
var ai Namer,ai是一个多字 (multiword) 数据结构,它的值时nil. 其本质上是一个指针,虽然不尽相同,指向接口的指针是非法的,没有任何作用,还会导致代码错误

- 类型 (比如结构体) 可以实现某个接口的方法集;这个实现可以描述为,该类型的变量上的每一个具体方法所组成的集合,包含了该接口的方法集.
- 实现了
Namer接口的类型变量可以赋值给ai(即 receiver 的值), 方法表指针 (method table ptr) 就指向了当前的方法实现。当另一个实现了Namer接口类型的变量被赋给ai,receiver的值和方法表指针也会相应改变 - 类型不需要显示声明它实现了某个接口: 接口被隐式的实现,多个类型可以实现同一个接口
- 实现某个接口的类型 (除了实现接口方法外) 可以有其他的方法
- 一个类型可以实现多个接口
- 接口类型可以包含一个实例的引用,该实例的类型实现了此接口 (接口是动态类型).
- 结构体
Square实现了接口Shaper, 所以可以将一个Square类型的变量赋值给 一个接口类型变量:areaIntf = sql - 接口变量包含一个指向
Square变量的引用,通过它可以调用Square上的Area()方法 - 接口变量 里包含了 接收者实例的值 和 指向对应方法表的指针
type Shaper interface { | |
Area() float32 | |
} | |
type Square struct { | |
side float32 | |
} | |
func (sq *Square) Area() float32 { | |
return sq.side * sq.side | |
} | |
func main() { | |
sq1 := new(Square) | |
sq1.side = 5 | |
var areaIntf Shaper | |
areaIntf = sq1 | |
fmt.Printf("The square has area: %f\n", areaIntf.Area()) | |
} |
# 2. 接口嵌套接口
- 一个接口可以包含一个或多个其他的接口,相当于将内嵌接口的方法列举在外层接口中一样
- 例如
File包含了ReadWrite和Lock的所有方法,还额外有一个Close()方法
type ReadWrite interface { | |
Read(b Buffer) bool | |
Write(b Buffer) bool | |
} | |
type Lock interface { | |
Lock() | |
Unlock() | |
} | |
type File interface { | |
ReadWrite | |
Lock | |
Close() | |
} |
# 3. 类型断言
检测和转换接口变量的类型
- 一个接口类型的变量 varI 可以包含任何类型的值,必须有一种方式来检测它的 动态 类型,运行时在变量中存储的值的实际类型
- 在执行过程中动态类型可能会有所不同,但总是可以分配给接口变量本身的类型。通常使用 类型断言 来测试,某个时刻
varI是否包含类型T的值.
v := varI.(T) //unchecked type assertion | |
//var 必须是一个接口变量,否则编译器会报错 : | |
invalid type assertion: varI.(T) (non-interface type (type of varI) on left) |
- 类型断言可能是无效的,编译器会尽力检查转换是否有效,但是不可能遇见所有的可能性.
- 转换在程序运行时失败会导致错误法发生,更安全的方式是使用以下形式来进行断言
- 转换合法:
v是varI转换到类型T的值,ok是true - 转换失败:
v是类型T的零值,ok是false, 也没有运行时错误
if v, ok := varI.(T); ok { // checked type assertion | |
Process(v) | |
return | |
} | |
// 只测试是否能够成功转换 | |
if _, ok := varI.(T); ok { | |
··· | |
} |
# 4. 类型判断
- 接口变量的类型也是可以使用一种特殊形式的 switch 来检测 :
type-switch
- t 得到了
areaIntf的值和类型,所有case语句中列举的类型 (nil除外) 都必须实现对应的接口 - 如果被检测类型没有在
case列举的类型中,就会执行default语句 type-switch进行运行时类型分析,case分支中不允许有fallthrough
switch t := areaIntf.(type) { | |
case *Square: | |
fmt.Printf("Type Square %T with value %v\n", t, t) | |
case *Circle: | |
fmt.Printf("Type Circle %T with value %v\n", t, t) | |
case nil: | |
fmt.Printf("nil value: nothing to check?\n") | |
default: | |
fmt.Printf("Unexpected type %T\n", t) | |
} | |
/* 输出 */ : Type Square *main.Square with value &{5} |
type-switch处理来自外部的,类型未知的数据时,例如 解析注入 JSON 或 XML 编码的数据,类型测试和转换会非常有用- 如下展示了一个类型分类函数,其拥有一个可变长度参数,可以是任意类型的数组,会根据数组元素的实际类型执行不同的动作:
func classifier(items ...interface{}) { | |
for i, x := range items { | |
switch x.(type) { | |
case bool: | |
fmt.Printf("Param #%d is a bool\n", i) | |
case float64: | |
fmt.Printf("Param #%d is a float64\n", i) | |
case int, int64: | |
fmt.Printf("Param #%d is a int\n", i) | |
case nil: | |
fmt.Printf("Param #%d is a nil\n", i) | |
case string: | |
fmt.Printf("Param #%d is a string\n", i) | |
default: | |
fmt.Printf("Param #%d is unknown\n", i) | |
} | |
} | |
} |
# 5. 测试一个值是否实现了某个接口
- 接口是一种契约,实现类型必须满足它
- 编写参数是接口变量的函数,使其更具有一般性
- 接口让代码更具有普适性
// 判断 v 是否实现了 Stringer 接口 | |
type Stringer interface { | |
String() string | |
} | |
if sv, ok := v.(Stringer); ok { | |
fmt.Printf("v implements String(): %s\n",sv.String()) | |
} |
# 6. 方法集与接口
- 作用于变量上的方法不区分变量是 指针还是值,但碰到接口类型值时,情况会变得复杂
- 接口变量中存储的具体值是不可寻址的,但不使用不当时编译器会给出错误
- 在接口上调用方法时,必须有和方法定义时相同的接收者类型或者是可以从具体类型
P直接辨识的:
- 指针方法可以通过指针调用
- 指针方法可以通过值使用
- 接收者是值的方法可以通过指针调用,因为指针会首先被解引用
- 接收者是指针的方法不可以通过值调用,因为存储在接口中的值没有地址
- Go 语言规范定义了接口方法集的调用规则:
- 类型 T 的可调用方法集合包含接受者为 *T 或 T 的所有方法集
- 类型 T 的可调用方法集包含接收者为 T 的所有方法
- 类型 *T 的可调用方法集不包含接收者为 T 的方法
# 7. 使用 Sorter 接口排序
- 要对一组数字或字符串排序,只需要实现三个方法:
- 反映元素个数的
Len() - 比较第
i和j个元素的Less(i,j) - 交换第
i和j个元素的Swap(i,j)
// Sort 函数接收一个接口类型的参数: Sorter | |
type Sorter interface { | |
Len() int | |
Less(i,j int) bool | |
Swap(i, j int) | |
} |
- 冒泡排序
Sorter实现
func Sort(data Sorter) { | |
for pass :=1; pass < data.Len(); pass++ { | |
if data.Less(i+1, i) { | |
data.Swap(i,i + 1) | |
} | |
} | |
} |
- 多种数据类型 基于 Sorter 接口的冒泡排序
package sort | |
type Sorter interface { | |
Len() int | |
Less(i, j int) bool | |
Swap(i, j int) | |
} | |
func Sort(data Sorter) { | |
for pass := 1; pass < data.Len(); pass++ { | |
for i := 0; i < data.Len()-pass; i++ { | |
if data.Less(i+1, i) { | |
data.Swap(i, i+1) | |
} | |
} | |
} | |
} | |
func IsSorted(data Sorter) bool { | |
n := data.Len() | |
for i := n - 1; i > 0; i-- { | |
if data.Less(i, i-1) { | |
return false | |
} | |
} | |
return true | |
} | |
// Convenience types for common cases | |
type IntArray []int | |
func (p IntArray) Len() int { return len(p) } | |
func (p IntArray) Less(i, j int) bool { return p[i] < p[j] } | |
func (p IntArray) Swap(i, j int) { p[i], p[j] = p[j], p[i] } | |
type StringArray []string | |
func (p StringArray) Len() int { return len(p) } | |
func (p StringArray) Less(i, j int) bool { return p[i] < p[j] } | |
func (p StringArray) Swap(i, j int) { p[i], p[j] = p[j], p[i] } | |
// Convenience wrappers for common cases | |
func SortInts(a []int) { Sort(IntArray(a)) } | |
func SortStrings(a []string) { Sort(StringArray(a)) } | |
func IntsAreSorted(a []int) bool { return IsSorted(IntArray(a)) } | |
func StringsAreSorted(a []string) bool { return IsSorted(StringArray(a)) } |
# 8. 读和写
- 读和写是软件中普遍的行为,一般用于 读写文件,缓存 (比如字节或字符串切片), 标准输入输出,标准错误以及网络连接,管道等等,或者 自定义类型。为了让代码尽可能通用,GO 采取了一致的方式来读写数据.
io包提供了用于读和写的接口io.Reader和io.Writer:
type Reader interface { | |
Read(p []byte) (n int,err error) | |
} | |
type Writer interface { | |
Write(p []byte) (n int,err error) | |
} |
- 只要类型实现了读写接口,提供
Read()和Write方法,就可以从中 读取或写入数据. - 一个对象是可读的,必须实现
io.Reader接口,
- 这个接口只有一个签名是
Read(p []byte) (n int,err error)的方法, - 它从调用它的对象读取数据,并把读取到的数据放入参数的字节切片中,返回读取字节数和一个
error对象,如果没有发生错误返回nil - 如果已经达到输入的尾端,会返回
io.EOF("EOF"), 如果读取过程中发送了错误,就会返回具体的错误信息
- 一个对象是可写的,其必须实现
io.worter接口
- 这个接口也只有一个签名是
Write(p []byte) (n int,err error)的方法 - 该方法将指定字节切片中的数据写入调用它的对象中,然后返回实际写入的字节数和一个
error对象 (如果没有发生错误就是nil).
- io 包中的 Readers 和 Writers 都是不带缓冲的,bufio 包提供了对应的带缓冲的操作,在读写 UTF-8 编码的文本时尤其有用.
# 9. 空接口
概念:空接口或者最小接口不包含任何方法,它对实现比作任何要求
任何其他类型都实现了空接口,(它不仅仅像
Java/C#中的Object引用类型)any或Any是空接口一个很好的别名 或 缩写空接口类似 Java/C# 中所有类的基类: Object 类,二者目标也很接近.
可以给一个空接口类型的变量
var val interface {}赋任何类型的值.
type Any interface{ } |
val可依次被赋予一个int,string和Person实例的值,然后使用type-switch来测试它的实际类型。每个interface{}- 变量在内存中占据两个字长:一个用来存储它包含的类型,另一个用来存储它包含的 数据或指向数据的指针
# 1. 构建通用类型或者包含不同类型变量的数组
- 给空接口定义一个别名类型
Element:
type Element interface{} |
- 定义一个容器类型的结构体
Vector, 包含一个Element类型元素的切片:
type Vector struct { | |
a []Element | |
} |
Vector能放置任何类型的变量,应为任何类型都实现了空接口,实际上Vector里放的每个元素都可以是不同类型的变量。为其定义一个At()方法用于返回第i个元素 :
func (p *Vector) At(i int) Element { | |
return p.a[i] | |
} |
- 定义一个
Set()方法用于设置第i个元素的值:
func (p *Vector) set(i int,e Element) { | |
p.a[i] = e | |
} |
Vector中存储的所有元素都是Element类型,要得到它们的原始类型 (unboxing: 拆箱) 需要用到类型断言- 类型断言总是在运行时才执行,因此它会产生运行时错误:
The Compiler rejects assertions guaranteed to fail
# 2. 复制数据切片至空接口切片
- Go 中 无法将
myType类型的数据切片直接复制到一个 空接口切片 中
/** | |
* 使用这种方式赋值会引起编译时报错 | |
* cannot use dataSlice (type [] myType) as type [] interface {} in assignment | |
*/ | |
var dataSlice []myType = FuncReturnSlice() | |
var interfaceSlice []interface{} = dataSlice |
- 空接口切片和
myType类型的切片在内存中的布局是不一样的,必须使用for-range语句来一个个显示赋值
var dataSlice []myType = FuncReturnSlice() | |
var interfaceSlice []interface{} = make([]interface{}, len(dataSlice)) | |
for i, d := range dataSlice { | |
interfaceSlice[i] = d | |
} |
# 3. 反射包
- 方法和类型的反射
- 通过反射可以分析一个结构体,反射是用程序检查其所拥有的结构,尤其是类型的一种能力;是元编程的一种形式
- 反射可以在运行时检查类型和变量,例如: 变量的大小,方法 和 动态的调用这些方法
- 对于没有源码的包,反射尤其有用,反射是一个强大的工具,除非真得有必要,否则应当避免使用
- 变量的最基本信息就是类型和值:反射包的 Type 用来表示一个 Go 类型,反射包的 value 为 Go 值提供了反射接口
reflect.TypeOf和reflect.ValueIf, 返回被检查对象的类型和值.i的值包含一个type和value, 反射可以从接口值反射到对象,也可以从对象反射回接口值
/* | |
* 反射实际上是通过检查一个接口的值,变量首先被转换成空接口 | |
*/ | |
func TypeOf(i interface{}) Type | |
func ValueOf(i interface{}) Value |
reflect 常用方法 :
| 方法签名 | 返回值 | 作用 |
|---|---|---|
| reflect.TypeOf(i interface{}) Type | i Type | 返回被检查对象的类型 |
| reflect.ValueOf(i interface{}) Value | i Value | 返回被检查对象的值 |
| v:= reflect.ValueOf(x) v.Kind() | v type | Kind 总是返回底层类型 |
| v.Interface() | val value | (还原) 得到接口的值 |
# 4. 通过反射修改 (设置) 值
| 方法签名 | 返回值 | 作用 |
|---|---|---|
| v.Canset() | bool | 测试 value 是否可设置 |
| v := reflect.ValueOf(x) | value | 传递 x 的拷贝创建 v,v 的改变无法影响原始的 x |
| v := reflect.ValueOf(&x) | value | 传递 x 的地址,v 的改变可影响 x |
| func (v Value) Elem() Value | value | 返回 v 持有的接口保管的值的 Value 封装 |
| func (v Value) setString(s string) | \ | 设置 v 持有值 |
# 5. 反射结构
- 有些时候需要反射一个结构类型.
NumField()方法返回结构内的字段数量;通过一个for循环用索引取得每个字段的值Field(i) - 通过索引
n来调用签名在结构体上的方法:Method(n).Call(nil) - 如果尝试修改结构体中的 不可导出字段 (首字母小写), 会得到一个错误
panic: reflect.Value.SetStringusing value obtained using unexported field |
- 结构体中只有被导出字段 (首字母大写) 才是可设置的,
type.Field(i).Name(得到结构体中第 i 个字段名)
type T struct{ | |
A int | |
B string | |
} | |
func main(){ | |
t := T{23,"skidoo"} | |
s := reflect.ValueOf(&t).Elem() | |
typeOfT := s.Type() | |
for i :=0; i < s.NumField(); i++{ | |
f := s.Field(i) | |
fmt.Printf("%d: %s %s = %v\n", i, | |
typeOfT.Field(i).Name, f.Type(), f.Interface()) | |
} | |
s.Field(0).SetInt(77) | |
s.Field(1).SetString("Sunset Strip") | |
fmt.Println("t is now", t) | |
} | |
输出: | |
0 | |
1 | |
t is now {77, SunsetStrip} |
# 10.Printf 和反射
GO 语言标准库中,反射的功能被大量的使用.fmt 包中的 printf (以及其他格式化输出函数) 都会使用反射来分析它的 ... 参数
Printf 的函数声明为:
- Printf 中的 ... 参数为空接口类型,
- Printf 使用反射包来解析这个参数列表。所以,Printf 能够知道每个参数的类型
- 使用 type-switch 来推导参数类型,并根据类型输出每个参数的值.
func Printf(format string,args ...interface{}) (n int,err error) |
# 11. 接口与动态类型
Go 的动态类型
- 经典面向对象语言 (c++,Java 和 c#) 中数据和方法被封装为类的概念:类包含两者且不能剥离
- Go 没有类:数据 (结构体或更一般的类型) 和 方法是一种松耦合的正交关系
- Go 中的接口跟 Java/C# 类似:都必须提供一个指定方法集的实现。但更加灵活通用:任何提供了接口方法实现代码的类型都隐式实现了该接口,而不用显示的声明
- Go 是唯一结合了接口值,静态类型检查 (该类型是否实现某个接口), 运行时动态转换的语言,并且不需要显示的声明类型是否满足某个接口.
- 接收一个 (或多个) 接口类型作为参数的函数,其实参可以是任何实现了该接口的类型变量。实现了某个接口的类型可以被传递给任何以此接口为参数的函数
动态方法调用
- Python,Ruby 这类语言,动态类型是延迟绑定的 (在运行时进行): 方法只是用参数和变量简单的调用,然后运行时才解析 (会产生更大的编码量和更多的测试工作)
- Go 的实现与此相反,通常需要编译器静态检查的支持:当变量被赋值给一个接口类型的变量时,编译器会检查其是否实现了改接口的所有函数.
- 如果方法调用作用于像 interface {} 的 "泛型" 上,可以通过类型断言来检查变量是否实现了相应接口
- Go 提供了动态语言的优点,却没有其他语言在运行时可能发送错误的缺点 (可以减少单元测试)
- Go 的接口提高了代码的分离度,改善了代码的复用性,使代码开发中的设计模式更容易实现.Go 接口还能实现依赖注入模式
接口的提取
- 提取接口 是非常有用的设计模式,可以减少需要的类型和方法数量,且不需要像传统的基于类的面向对象语言那样维护整个类的层次结构
- Go 可以让开发者找出自己写的程序中的类型。如果有一些拥有共同行为的对象,并且开发者想要抽象出这些行为,就可以创建一个接口来使用.
- 类型想要实现某个接口,本身无需改变,只需要在这个类型上实现新的方法;不用提前设计出所有的接口, 整个设计可以持续演进,而不用废弃之前的决定.
显式地指明类型实现了某个接口
- 希望某个接口的类型显式的声明它们实现了这个接口,可以向方法集中添加一个具有描述性名字的方法.
type Fooer interface { | |
Foo() | |
ImplementsFooer() | |
} |
- 类型
Bar必须实现ImplementsFooter方法来满足Fooer()接口,以清楚记录这个事实 - 大部分代码并不使用这样的约束,因为限制了接口的实用性
- 有些时候,这样的约束在大量相似的接口中被用来解决歧义.
type Bar struct{} | |
func (b Bar) ImplementsFooer() {} | |
func (b Bar) Foo() {} |
空接口和函数重载
- Go 语言中函数重载可以用可变参数 ...T 作为函数最后一个参数来实现。如果将 T 换为空接口,那么任何变量都是满足 T (空接口) 类型的,这样就允许传递任何数量任何类型的参数给函数,即重载的实际含义
- 函数
fmt.Printf通过枚举slice类型的实参动态确定所有参数的类型。并查看每个类型是否实现了String()方法
// 函数 fmt.Printf 就是这样实现的 | |
fmt.Printf(format string,a ...interface{}) (n int,errno error) |
接口的继承
- 当一个类型包含 (内嵌) 另一个类型 (实现了一个或多个接口) 的指针时,这个类型就可以使用 (另一个类型) 所有与的接口方法.
type Task struct { | |
Command string | |
*log.Logger | |
} |
task的工厂方法
func NewTask(command string,logger *log.Logger) *Task { | |
return &Task{command, logger} | |
} |
- 当 log.Logger 实现了 Log () 方法后,Task 的实例 task 就可以调用该方法:
task.Log() |
- 类型可以通过继承多个接口来提供像
多继承一样的特性:
type ReaderWriter struct { | |
*io.Reader | |
*io.Writer | |
} |
- 以上原理被应用于整个 Go 包,多态用得越多,代码就相对越少。这被认为是 Go 编程中的重要的最佳实践
- 有用的接口可以在开发的过程中被归纳出来。添加新接口非常容易,因为已有的类型不用变动 (仅仅需要实现新接口的方法).
- 已有的函数可以拓展为使用接口类型的约束性参数:通常只有函数签名需要改变。对比于基类的 oo 类型的语言在这种情况下则需要适用整个类型层次结构的变化
# 12.Go 中的面向对象
Go 没有类,而是松耦合的类型,方法对接口的实现.
- 封装 (数据隐藏): Go 将其他 oo 语言的多个访问层次简化为 2 层:
- 包的范围:通过表示符首字母小写,对象 只在自己所在的包内可见
- 可导出的:通过标识符首字母大写,对象 对所在包以外的也可见
- 继承:用组合实现:内嵌一个 (或多个) 包含想要的行为 (字段和方法) 的类型;多重继承可通过内嵌多个类型实现
- 多态:用接口实现:某个类型的实例可以赋给其所实现的任意接口类型的变量。类和接口是松耦合的,并且多继承可以通过实现多个接口实现.
- GO 接口间是不相关的,且是大规模变成和可适应的演进类型设计的关键.
# 4. 读写数据
# 1. 读取用户的输入
Go 语言获取用户的键盘 (控制台) 输入,从键盘和标准输入 os.Stdin 读取输入,最简单的办法是使用 fmt 包提供的 Scan 和 Sscan 开头的函数.
- fmt 包下的 scan 系列方法,扫描来自标准输入的文本或字符,将空格分隔的值依次存放到后续的参数内.(传递参数地址接收)
| 方法签名 | 作用 |
|---|---|
func Scanf (format string,a ...interface{}) (n int,err error) | 根据 format 将读取值赋予函数参数 |
func Fscanf (r io.Reader,format string.a ...interface{}) (n int,err error) | 从 r 扫描文本,根据 format 格式化值赋予参数 |
func Sscanf (str string, format string, a ...interface{}) (n int, err error) | 扫描 str 根据 format 格式化值赋予参数 |
func Scan (a ...interface{}) (n int,err error) | 扫描标准输入文本,读取以空格分隔的值赋予参数 |
func Fscan (r io.Reader,a ...interface{}) (n int,err error) | 扫描 str 将成功读取的空白分隔值保存至参数。读取值少于参数值,则返回错误 |
func Sscan (str string,a ...interface{}) (n int,err error) | 扫描 str, 读取空白分隔值保存到参数,换行视为空白,读取值少于参数报错 |
func Sscanln (a ...interface{}) (n int,err error) | 类似 scan, 遇到换行才会停止,最后条目必须有换行或者达到结束位置 |
func Fscanln (r io.Reader,a ...interface{}) (n int,err error) | 类似 Fscan, 遇到换行停止扫描,终止位置必须有换行或者到达结束位置 |
func Sscanln (str string,a ...interface{}) (n int,err error) | 类似 Sscan, 换行时才停止扫描,终止位置必须有换行或者到达结束位置 |
bufio包提供缓冲读取 (buffered reader) 来读取数据
inputReader是一个指向bufio.Reader的指针.inputReader := bufo.NewReader(os.Stdin)会创建一个读取器,并将其与标准输入绑定.bufio.NewReader()构造函数的签名为:func NewReader(rd io.Reader) *Reader- 函数的实参可以是满足
io.Reader接口的任意对象 (任意包含有适当的Read()方法的对象) - 函数返回一个新的带缓冲的
io.Reader对象,将从指定读取机器 (例如os.Stdin) 读取内容 - 返回的读取器对象提供一个方法
ReadString(delim byte), 该方法从输入中读取内容,直到碰到 delim 指定的字符,然后将读取到的内容连同delim字符一起放到缓冲区
- 函数的实参可以是满足
ReadString返回读取到的字符串,如果碰到错误则返回nil, 如果一直读取到文件结束,则返回读取到的字符串和io.EOF如果读取过程中没有遇到delim字符,将返回错误err != nil屏幕是标准输出
os.Stdout,os.Stderr用于显示错误信息,大多数情况下等同于os.Stdout
inputReader := bufio.NewReader(os.Stdin) | |
input, err := inputReader.ReadString('\n') |
缓冲读取:
| 函数签名 | 作用 |
|---|---|
func NewReader (rd io.Reader) *Reader | 创建默认大小缓冲,从 r 读取的 * Reader |
func NewReaderSize (rd io.Reader,size int) *Reader | 创建 size 尺寸的缓冲,从 r 读取 * Reader |
func (b *Reader) Reset (r io.Reader) | 丢弃缓冲中的数据,清除错误,将 b 设为下层,从 r 读取数据 |
func (b *Reader) Buffered () int | 返回缓冲中现有的可读取的字节数 |
func (b *Reader) Peek (n int) ([]byte, error) | 返回下 n 个字节,不会移动位置 |
func (b *Reader) Read (p []byte) (n int,err error) | 返回写入 p 的字节数。读取到结尾时 n=0,err=io.EOF |
func (b *Reader) ReadByte (c byte,err error) | 读取并返回一个字节,没有可用数据返回错误 |
func (b *Reader) UnreadByte () error | 吐出读取的最后一个字节.(多次调用会报错) |
func (b *Reader) ReadRune () (r rune,size int,err error) | 读取一个 unicode 码,返回码值,长度 |
func (b *Reader) UnreadRune () error | 吐出最近一次 ReadRune 读取的 Unicode 码值 |
func (b *Reader) ReadLine (line []byte,isPrefix bool,err error) | 返回一行数据,不包括行尾标志的字节 |
func (b *Reader) ReadSlice (delim byte) (line []byte,err error) | 读取直到第一次遇到 delim 字节,返回已读取的字节切片 |
func (b *Reader) ReadBytes (delim byte) (line []byte,err error) | 读取直到第一次遇到 delim 字节,返回已读取的字节切片 |
func (b *Reader) ReadString (delim byte) (line string,err error) | 读取直到第一次遇到 delim 字节,返回已读取的字节的字符串 |
func (b *Reader) WriteTo (w io.Writer) (n int64,err error) | 实现了 io.Writer 接口 |
# 2. 文件读写
# 1. 读文件
- Go 语言中,文件使用指向 os.File 类型的指针来表示,也叫做文件句柄,标准输入
os.Stdin和 标注输出os.Stdout的类型都是*os.File
| 属性 | 作用 |
|---|---|
| os.Stdin | 指向标准输入 |
| os.Stdout | 指向标准输出 |
| os.Stderr | 指向标准错误 |
变量
inputFile是*os.File类型的。该类型是一个结构,表示一个打开文件的描述符 (文件句柄). 使用os包中的Open函数来打开文件,函数的参数是文件名,类型为string. 下面程序中是以只读模式打开input.dat文件.文件不存在,或者程序没有足够的权限打开文件,Open 函数会返回一个错误:
inputFile, inputError = os.Open("input.dat")文件正常打开,使用
defer inputFile.Close()语句确保在程序退出前关闭该文件。使用bufio.NewReader获取读取器变量.通过使用
bufio包提供的读取器 (写入器类似), 可以方便的操作相对高层的string对象,避免操作者底层的字节在无限循环中使用
ReadString('\n')或ReadBytes('\n')将文件内容逐行读取出来Unix和Linux的行结束符是\n, 而Windows的行结束符是\r\n. 在使用ReadString和ReadBytes方法的时候,无需关心操作系统的类型,直接使用\n即可,亦可使用ReadLine()方法来实现相同的功能读取到文件末尾,变量 readerError 的值将变成非空 (其值常量为
io.EOF) 就会执行 return 语句退出循环
func main() { | |
inputFile, inputError := os.Open("input.dat") | |
if inputError != nil { | |
fmt.Printf("An error occurred on opening the inputfile\n" + | |
"Does the file exist?\n" + | |
"Have you got acces to it?\n") | |
return // exit the function on error | |
} | |
defer inputFile.Close() | |
inputReader := bufio.NewReader(inputFile) | |
for { | |
inputString, readerError := inputReader.ReadString('\n') | |
fmt.Printf("The input was: %s", inputString) | |
if readerError == io.EOF { | |
return | |
} | |
} | |
} |
- 将整个文件的内容读取到一个字符串里 :
io/ioutil包里的ioutil.ReadFile()方法,- 该方法第一个返回值的类型是
[]byte, 里面存放读取到的内容, - 第二个返回值是错误,如果没有错误发生,第二个值为
nil. 函数WriteFile()可以将[]byte值写入文件
func main() { | |
inputFile := "products.txt" | |
outputFile := "products_copy.txt" | |
buf, err := ioutil.ReadFile(inputFile) | |
if err != nil { | |
fmt.Fprintf(os.Stderr, "File Error: %s\n", err) | |
// panic(err.Error()) | |
} | |
fmt.Printf("%s\n", string(buf)) | |
err = ioutil.WriteFile(outputFile, buf, 0644) // oct, not hex | |
if err != nil { | |
panic(err.Error()) | |
} | |
} |
- 带缓冲的读取
- 多数情况下,文件的内容是不按行划分的,或者是一个二进制文件. ReadString () 就无法使用了,可以使用 bufio.Reader 的 Read (), 只接收一个参数:
buf := make([]byte,1024) | |
//n 表示读取到的字节数 | |
n, err := inputReader.Read(buf) | |
if (n == 0) {break} |
按列读取文件的数据
- 如果文件是按列并用空格分割的,可以使用 fmt 包提供的以 FScan 开头的一系列函数来读取.
func main() {
file, err := os.Open("products2.txt")
if err != nil {
panic(err)
}defer file.Close()
var col1, col2, col3 []string
for {
var v1, v2, v3 string
_, err := fmt.Fscanln(file, &v1, &v2, &v3)
// scans until newlineif err != nil {
break}col1 = append(col1, v1)
col2 = append(col2, v2)
col3 = append(col3, v3)
}fmt.Println(col1)
fmt.Println(col2)
fmt.Println(col3)
}path包中包含一个子包filepath, 这个子包提供了跨平台的函数,用于处理文件名和路径.- 例如:
Base()函数用于获取路径中的最后一个元素 (不包含后面的分隔符)
import "path/filepath"
filename := filepath.Base(path)
compress包提供了,读取压缩文件的功能,支持的压缩文件格式为: bzip, flate, gzip, lzw 和 zlib.
# 2. 写文件
除了文件句柄,还需要
bufio的writer.- 以只读模式打开文件
output.dat, 文件不存在则自动创建 OpenFile函数有三个参数:文件名,一个或多个标志 (使用逻辑运算符 "|" 连接), 使用的文件权限os.O_RDONLY: 只读os.O_WRONLY: 只写os.O_CREATE: 创建,如果指定文件不存在,就创建该文件.os.O_TRUNC: 截断,如果指定文件已存在,就该文件长度截为 0- 读文件时,文件的权限是被忽略的,所以使用
OpenFile时传入的第三个参数可以用 0. - 写文件时,不论是
Unix还是Windowx都需要使用 0666
outputFile, outputError := os.OpenFile("output.dat", os.O_WRONLY|os.O_CREATE, 0666)
// 创建一个写入器 (缓冲区) 对象outputWriter := bufio.NewWriter(outputFile)
// 将字符写入缓冲区outputWriter.WriteString(outputString)
// 缓冲区的内容完全写入文件outputWriter.Flush()
/** 写入简单内容时,使用 fmt.Fprintf 直接将内容写入文件
* fmt 包中 F 开头的 Print 函数可以直接写入任何 io.Writer, 包括文件
*/
fmt.Fprintf(outputFile, "Some test data.\n")
os.Stdout.WriteString("hello, world\n")输出内容到屏幕f, _ := os.OpenFile("test",os.O_CREATE|os.O_WRONLY,0666)以只写模式创建或打开文件f.WriteString()不使用缓冲区,直接将内容写入文件
- 以只读模式打开文件
文件拷贝
- 拷贝一个文件到另一个文件,最简单的方式就是使用 io 包
- defer , 当打开文件时发送错误,
defer仍然能够确保src.Close()执行,如果不关闭 src 文件会一直保持打开占用资源
func main() { | |
CopyFile("copy","17.jpg") | |
fmt.Println("Copy done!") | |
} | |
func CopyFile(dstName, srcName string) (written int64, err error) { | |
src, err := os.Open(srcName) | |
if err != nil { | |
return | |
} | |
defer src.Close() | |
dst, err := os.Create(dstName) | |
if err != nil { | |
return | |
} | |
defer dst.Close() | |
return io.Copy(dst,src) | |
} |
# 3. 从命令行读取参数
- os 包中有一个 string 类型的切片变量
os.Args, 用来处理一些基本的命令行参数,它在程序启动后读取命令行输入的参数- 命令行参数会放置在切片 os.Args [] 中 (以空格分隔), 从索引 1 开始 (
os.Args[0]放的是程序本身的名字)
- 命令行参数会放置在切片 os.Args [] 中 (以空格分隔), 从索引 1 开始 (
func main() { | |
who := "Alice " | |
if len(os.Args) > 1 { | |
who += strings.Join(os.Args[1:]," ") | |
} | |
fmt.Println("Good Morning",who) | |
} |
- flag 包中有一个扩展功能来解析命令行选项,但是通常被用来替换基本常量,例如,某些情况下给常量一些不一样的值
flag 包中有一个 Flag 被定义成含有如下字段的结构体:
typr Flag struct { | |
Name string // name as it appears on command line | |
Usage string // help message | |
Value Value // value as set | |
DefValue string // default value (as text); for usage message | |
} |
模拟 Unix 的 echo 功能
flag.Parse()扫描参数列表 并设置flag,flag.Arg(i), 表示第 i 个参数.Parse()之后flag.Arg(i)全部可用,flag.Arg(0)就是第一个真实的flagflag.Narg()返回参数的数量。解析后 flag 或常量就可以使用flag.PrintDefaults()打印 flag 的使用帮助信息flag.VisitAll(fn func(*Flag)): 按照字典顺序遍历flag, 并对每个标签调用fnflag定义类型 :flag.Bool(),flag.Int(),flag.Float64,flag.String()
var NewLine = flag.Bool("n", false, "print newline") // echo -n flag, of type *bool | |
const ( | |
Space = " " | |
Newline = "\n" | |
) | |
func main() { | |
flag.PrintDefaults() | |
flag.Parse() // Scans the arg list and sets up flags | |
var s string = "" | |
for i := 0; i < flag.NArg(); i++ { | |
if i > 0 { | |
s += " " | |
if *NewLine { // -n is parsed, flag becomes true | |
s += Newline | |
} | |
} | |
s += flag.Arg(i) | |
} | |
os.Stdout.WriteString(s) | |
} |
# 4. buffer 读取文件
结合使用缓冲读取文件和命令行 flag 解析,输出内容
- 不添加参数时,cmd 输入什么就输出什么
- 参数是文件名时,如果文件存在就打印文件内容到屏幕,
func cat(r *bufio.Reader) { | |
for { | |
buf, err := r.ReadBytes('\n') | |
fmt.Fprintf(os.Stdout, "%s", buf) | |
if err == io.EOF { | |
break | |
} | |
} | |
return | |
} | |
func bufRead() { | |
flag.Parse() | |
if flag.NArg() == 0 { | |
cat(bufio.NewReader(os.Stdin)) | |
} | |
for i := 0; i < flag.NArg(); i++ { | |
f, err := os.Open(flag.Arg(i)) | |
if err != nil { | |
fmt.Fprintf(os.Stderr, "%s:error reading from %s: %s\n", os.Args[0], flag.Arg(i), err.Error()) | |
continue | |
} | |
cat(bufio.NewReader(f)) | |
f.Close() | |
} | |
} |
# 5. 切片读写文件
切片提供了 Go 中处理 I/O 缓冲的标准方式,
如下 cat 函数中,在一个切片缓冲内使用无限 for 循环 (直到文件尾部 EOF) 读取文件,并写入到标准输出 ( os.Stdout )
func cat(f *os.File) { | |
const NBUF = 512 | |
var buf [NBUF]byte | |
for { | |
switch nr,err := f.Read(buf[:]); { | |
case nr < 0: | |
fmt.Fprintf(os.Stderr,"cat: error reading: %s\n",err.Error()) | |
os.Exit(1) | |
case nr == 0: //EOF | |
return | |
case nr >0: | |
if nw, ew := os.Stdout.Write(buf[0:nr]); nw != nr { | |
fmt.Fprintf(os.Stderr,"cat: error writing: %s\n",ew.Error()) | |
} | |
} | |
} | |
} |
# 6. defer 关闭文件
defer 关键字,对于函数结束时关闭打开的文件非常有用 :
// 在函数 return 后执行 f.Close () 关闭打开的文件 | |
func data(name string) string { | |
f, _ := os.OpenFile(name, os.O_RDONLY, 0) | |
defer f.Close() //return 后关闭文件 | |
centos, _ := ioutil.ReadAll(f) | |
return string(contents) | |
} |
# 7. 接口使用实际案例: fmt.Fprintf
程序 io_interfaces.go 阐述了 io 包的接口概念
func main() { | |
// unbuffered | |
fmt.Fprintf(os.Stdout, "%s\n", "hello world! - unbuffered") | |
// buffered: os.Stdout implements io.Writer | |
buf := bufio.NewWriter(os.Stdout) | |
// and now so does buf. | |
fmt.Fprintf(buf, "%s\n", "hello world! - buffered") | |
buf.Flush() //Flush 方法将缓冲中的数据写入下层的 io.Writer 接口。 | |
} |
fmt.Fprintf() 函数的实际签名 :
fmt.Fprintf()依据指定的格式向第一个参数内写入字符串,参数一必须实现了io.Writer接口Fprintf()能够写入任何类型,只要其实现了write方法,包括os.Stdout, 文件 (如: os.File), 管道,网络,连接,通道等等.- 同样也可以使用
bufio包中缓冲写入.bufio包中定义了type Writer struct{...} - 工厂函数
func NewWriter(wr io.Writer) (b *Writer): 传递一个io.Writer类型参数,返回一个带缓冲的 - 其适合任何形式的缓冲读写,缓冲读写最后要使用
Flush(), 否则最后的输出不会被写入
func Fprintf(w io.Writer, format string, a ...interface{}) (n int,err error) | |
// 其参数不是写入一个文件,而是写入一个 io.Writer 接口类型的变量 | |
type Writer interface { | |
Write(p []byte) (n int,err error) | |
} | |
//bufio.Writer 实现了 Write 方法: | |
func (b *Writer) Write(p []byte) (nn int,err error) |
# 8. JSON 数据格式
数据结构要在网络中传输或保存到文件,就必须对其编码和解码;目前存在多种编码格式: JSON,XML,gob,Goole 缓冲协议,等等.Go 语言支持这些所有的编码格式
结构可能包含二进制数据,如果将其作为文本打印,可读性很差,结构内部可能包含匿名字段,而不清楚数据的用意.
通过把数据转换成纯文本,使用命名的字段来标注,让其具有可读性。这样的数据可以通过网络传输,而且与平台无关,任何类型的应用都能够读取和输出,不与操作系统和编程语言的类型相关.
序列化是在内存中把数据转换成指定格式 (data -> string), 反之亦然 (string -> data structure)
编码是输出一个数据流 (实现了
io.Writer接口); 解码是从一个数据流 (实现了 io.Reader) 输出到一个数据结构.- 数据结构 --> 指定格式 =
序列化或编码(传输之前) - 指定格式 --> 数据格式 =
反序列化或解码(传输之后)
- 数据结构 --> 指定格式 =
XML 被广泛的应用,但是 JSON 更加简洁、轻量 (占用更少的内存、磁盘及网络带宽) 和更好的可读性
encoding/json
| 方法 | 作用 |
|---|---|
func NewEncoder (w io.Writer) *Encoder | 创建一个将数据写入 w 的 * Encoder |
func Marshal (v interface{}) ([]byte, error) | 返回 v 的 json 编码 |
JSON 与 Go 类型对应如下:
- bool 对应 Json 的 boolean
- float64 对应 JSON 的 Number
- string 对应 JSON 的 string
- nil 对应 JSON 的 null
不是所有的数据都可以编码为 JSON 类型,只有验证通过的数据结构才能被编码:
- JSON 对象只支持字符串类型的 Key; 编码 Go map 类型,map 必须是 map [string] T (T 是 json 包中支持的任何类型)
- Channel, 复杂类型和函数类型不能被编码
- 不支持循环数据结构;会引起序列化进入一个无限循环
- 指针可以被编码,实际上是对指针指向的值进行编码 (或者指针是 nil)
反序列化
func Unmarshal(data []byte,v interface{}) error把JSON解码为数据结构对
JSON数据进行解码时,首先创建结构体用来保存解码的数据:var v struct 并调用 json.Unmarshal(jsonData,&v)解析
[]byte中的JSON数据并将结果存入指针 &v 指向的地址虽然反射能够让 JSON 字段尝试匹配目标结构字段;但是只有真正匹配上次啊会填充数据,没有匹配到直接忽略
解码任意数据
json包使用map[string]interface{}和[]interface存储任意的JSON对象和数组;其可以被反序列化为任何的JSON blob存储到接口值中
// 将 JSON 数据存储在变量 b 中b := []byte(`{"Name": "Wednesday", "Age": 6, "Parents": ["Gomez", "Morticia"]}`)
// 无需了解这个数据结构,可以直接使用 Unmarshal 将数据保存在接口值中var f interface{}
err := json.Unmarshal{b,&f}
//f 指向的是一个 map,key 是一个字符串,value 是自身存储作为空接口类型的值map[string]interface{} {
"Name": "Wednesday",
"Age": 6,
"Parents": []interface{} {
"Gomez",
"Morticia",
},
}// 访问这个数据可以使用类型断言m := f.(map[string]interface{})
/** 通过 for range 语法和 typeswitch 来访问其实际类型
* 通过这种方式,可以处理位置的 JOSN 数据,同时确保类型安全
*/
for k, v := range m {
switch vv := v.(type) {
case string:
fmt.Println(k, "is string", vv)
case int:
fmt.Println(k, "is int", vv)
case []interface{}:
fmt.Println(k, "is an array:")
for i, u := range vv {
fmt.Println(i, u)
}default:
fmt.Println(k, "is of a type I don’t know how to handle")
}}- 如果事先已知 JSON 数据类型,可以定义一个适当的结构并对 JSON 数据反序列化.
// 定义接收数据的结构体typr FamilyMember struct {
Name stringAge intParents []string
}// 反序列化 JSON 数据var m FamilyMembererr := josn.Unmarshal(b, &m)
编码和解码流
json包提供Decoder和Encoder类型来支持常用 JSON 数据流读写.NewDecoder和NewEncoder函数分别封装了io.Reader和io.Writer接口.
func NewDecoder(r io.Reader) *Decoder | |
func NewEncoder(w io.Writer) *Encoder |
- 将 JSON 直接写入文件,可以使用 json.NewEncoder 初始化文件 (或者任何实现 io.Writer 的类型), 并调用 Encode (); 与之相应的是使用 json.NewDecoder 和 Decode () 函数
func NewDecoder(r io.Reader) *Decoder | |
func (dec *Decoder) Decode(v interface{}) |
# 9.XML 数据格式
- 如同 JSON 包一样,XML 也有
Marshal()和UnMarshal()从 XML 中编码和解码数据;但其可以从文件中读取和写入 - 同 JSON 的方式一样,XML 数据也可以序列化为结构,或者从结构反序列化为 XML 数据
- xml 包定义了若干 XML 标签类型: StartElement, Chardata (从开始标签到结束标签之间的文本),EndElement, Comment, Directive 或 Proclnst
- xml 包中同样定义了一个结构解析器:
NewParser方法持有一个io.Reader并生成一个解析器对象,还有一个Token()方法返回输入流的下一个XML token. 在输入流结尾处会返回(nil, io.EOF) - XML 文本被循环处理直到
Token()返回一个错误,因为到达文件尾部,通过type-switch可以根据 XML 标签进一步处理.Chardata中的内容是一个[]byte, 通过字符串转换让其可读性变得更强
# 10.Gob 传输数据
- Gob 是 Go 以二进制形式序列化和反序列化程序数据的格式
- Gob 特定地用于纯 Go 的环境中,两个用 GO 写的服务器之间通信更加高效和优化
- Gob 只有可导出的字段会被编码,零值会被忽略。在解码结构体是,只有同时匹配名称和可兼容型的字段才会被解码
# 11.Go 数据加密
- 网络传输的数据必须加密,防止被 hacker (黑客) 读取或篡改,并且保证发出的数据和接收到的数据校验和一致.
has包:实现了adler32,crc32,crc64和fnv校验;crypto包:实现了其它hash算法,例如md4,md5,sha1等。以及完整实现aes,blowfish,rc4,rsa,xtea等加密算法.- 通过调用
sha1.New()创建了一个新的hash.Hash对象,用来计算SHA1校验值.Hash类型实际上是实现了io.Writer的接口 - 通过
io.WriteString或 hasher.Write 将给定的[]byte附加到当前的hash.Hash对象中
func main() { | |
hasher := sha1.New() | |
io.WriteString(hasher, "test") | |
b := []byte{} | |
fmt.Printf("Result: %x\n", hasher.Sum(b)) | |
fmt.Printf("Result: %d\n", hasher.Sum(b)) | |
// | |
hasher.Reset() | |
data := []byte("We shall overcome!") | |
n, err := hasher.Write(data) | |
if n!=len(data) || err!=nil { | |
log.Printf("Hash write error: %v / %v", n, err) | |
} | |
checksum := hasher.Sum(b) | |
fmt.Printf("Result: %x\n", checksum) | |
} |
# 5. 错误处理与测试
Go 没有像
java和.NET中的try/catch异常机制:不能执行抛出异常操作。但是有一套defer-panic-and-recover机制Go 设计者认为 try/catch 机制的使用太泛滥,而且底层向更高级的层级抛异常太耗费资源. Go 设计的机制也可以 "捕捉" 异常,但是更轻量,且只应该作为 (处理错误的) 最后手段.
Go 处理普通错误时,通过在函数和方法中返回错误对象作为它们的唯一或最后一个返回值 -- 如果返回 nil, 则没有错误发生 -- 并且主调 (calling) 函数总是应该检查收到的错误.
永远不要忽略错误,否则可能会导致程序崩溃!!
panic and recover是用来处理真正的异常,(无法预测的错误) 而不是普通的错误.库函数通常必须返回某种错误提示给主调 (calling) 函数
Go 检查和报告错误条件的惯有方式:
- 产生错误的函数会返回两个变量,一个值和一个错误码;如果后者是
nil则是成功,非nil就是发生了错误 - 为了防止发生错误时正在执行的函数 (如果有必要甚至会是整个程序) 被终止,在调用函数后必须检查错误
- 产生错误的函数会返回两个变量,一个值和一个错误码;如果后者是
为了更清晰的代码,一个总是使用包含错误值变量的 if 符合语句,显示错误信息可以使用
fmt.Printf或者是log中对应的方法,如果程序终止也没关系的话升至可以使用panic
# 1. 错误处理
- Go 有一个预先定义的
error接口类型:- 错误值用来表示异常状态;errors 包中有一个 errorString 结构体实现了 error 接口.
- 程序出错时可以使用 os.Exit (1) 来终止运行
typr error interface { | |
Error() string | |
} |
- 定义错误
- 定义一个型的错误类型,可以用
errors包中的errors.New函数接收合适的错误信息来创建
- 定义一个型的错误类型,可以用
err := error.New("math - square root of negative number") |
由于
fmt.Printf会自动调用string()方法,所以错误信息 "Error: error message" 会打印出来。通常 (错误信息) 都会有像 "Error:" 这样的前缀,所以错误信息不要以大写字母开头大部分情况下自定义错误结构类型很有意义,可以包含除了 (低层级的) 错误信息之外的信息。例如,正在进行的操作 (打开文件等), 全路径或名字.
如果有不同错误条件可能发生,对实际的错误使用类型断言或者类型判断 (type-switch) 是很有用的,可以根据错误场景做一些补救和恢复操作
// err != nil | |
if e, ok := err.(*os.PathError); ok { | |
// remedy situation | |
} | |
// 错误类型断言 | |
switch err := err.(type) { | |
case ParseError: | |
PrintParseError(err) | |
case PathError: | |
PrintPathError(err) | |
... | |
defalut: | |
fmt.Printf("Not a special error,just %s\n",err) | |
} |
- 错误类型命名都遵循同一种命名规范:错误类型以 "Error" 结尾,错误变量以 "err" 或 "Err" 开头
syscall是低阶外部包,用来提供基本调用的原始接口。返回封装整数类型错误码的syscall.Errno; 类型 syscall.Errno 实现了Error接口
// 大部分 syscall 函数都返回一个结果和可能的错误 | |
r, err := syscall.Open(name, mode, perm) | |
if err != nil { | |
fmt.Println(err.Error()) | |
} |
fmt 创建错误对象
- 返回包含错误参数的更有信息量的字符串,可以用
fmt.Errorf()来实现。和fmt.Printf()完全一样,接收一个或多个格式化占位符的格式化字符串和相应数量的占位变量。和打印信息不同的是它用信息生成错误对象
// 生成并返回一个错误对象if f < 0 {
return 0, fmt.Errorf("math: ")
}// 从命令行读取输入是,加入 help 标志,可以用有用的错误信息产生一个错误if len(os.Args) > 1 && (os.Args[1] == "-h" || os.Args[1] == "--help") {
err = fmt.Errorf("usage: %s infile.txt outfile.txt", filepath.Base(os.Args[0]))
return}- 返回包含错误参数的更有信息量的字符串,可以用
# 2. 运行时异常和 panic
- 当发生数组下标越界或类型断言失败这样的运行时错误时,Go 运行时会触发运行时
panic, 伴随着程序的崩溃抛出一个runtime.Error接口类型的值。这个错误值有个RuntimeError()方法用于区别普通错误. panic可以直接从diamante初始化:当错误条件很严苛且不可恢复,程序不能运行时,可以使用panic函数产生一个终止程序的运行时错误,panic接收一个任意类型的参数,通常是字符串,在程序死亡时被发硬出来。负责程序终止并给出调试信息.- 当发生错误必须终止程序时,
panic可以用于错误处理模式:
if err != nil { | |
panic("ERROR occurred:" + err.Error()) | |
} |
- 多层嵌套的函数中调用
panic, 可以马上终止当前函数的执行,所有的defer语句都会保证执行并把控制权交还给接收到panic的函数调用者。并向上冒泡直到最顶层,并执行 (每层的)defer, 在栈顶处程序崩溃,并在命令中用传给 panic 的值报告错误情况。此终止过程就是 panicking - 标准库中有许多包含
Must前缀的函数,像regexp.MustComplie和template.Must; 当正则表达式或模板中转入的转换字符导致错误时,这些函数会panic
# 3. 从 panic 中恢复 (Recover)
recover内建函数被用于从panic或 错误场景中回复:让程序可以从panicking重新获得控制权,停止终止过程进而回复正常执行.recover只能在defer修饰的函数中使用;用于取得panic调用中传递过来的错误值,如果正常执行,调用recover会返回nil, 且没有其它效果panic会导致栈被展开直到defer修饰的recover()被调用或程序中止- 案例:
protect函数调用函数参数 g 来保护调用者防止从 g 中抛出的运行时panic, 并展示panic信息
- 案例:
// 类似于 Java 和 .NET 语言中的 catch 块 | |
func protect(g func()) { | |
defer func() { | |
log.Println("done") | |
// println executes normally even if there is a panic | |
if err := recover(); err != nil { | |
log.Printf("run time panic: %v", err) | |
} | |
}() | |
log.Println("start") | |
g() // possible runtime-error | |
} |
log包实现了简单的日志功能:默认的log对象向标准错误输出中写入并打印日志信息的日期和时间。除了Println和printf函数,其它致命性函数都会在写完日志信息后调用os.Exit(1), 退出函数也是如此。而panic效果的函数也会在写完日志信息后调用panic; 可以在程序必须终止 或 发生临界错误时使用.- 展示 panic, defer 和 recover 结合使用的完整案例
func badCall() { | |
panic("bad end") | |
} | |
func test() { | |
defer func() { | |
if e := recover(); e != nil { | |
fmt.Printf("panicing %s \r\n",e) | |
} | |
}() | |
badCall() | |
fmt.Printf("After bad call\r\n") // <-- wordt niet bereikt | |
} | |
func main() { | |
fmt.Printf("Calling test\r\n") | |
test() | |
fmt.Printf("Test completed\r\n") | |
} | |
// 输出结果 | |
Calling test | |
Panicing bad end | |
Test completed |
defer-panic-recover在某种意义上也是一种像if,for的控制流机制.- Go 标准库中许多地方都使用了这种机制,例如
json包中的解码和regexp包中的Compile函数. - Go 库的原则是及时在包内部使用了
panic, 在它的对外接口 (API) 中也必须使用recover处理成返回显示的错误.
# 4. 自定义包中的错误处理和 panicking
自定义包实现规范:
- 在包内部,总是应该从
panic中recover: 不允许显示的超出包范围的panic() - 向包的调用者返回错误值 (而不是 panic)
- 在包内部,总是应该从
在包内部,特别是非导出函数中有很深层次的嵌套调用时,将 panic 转换成 error 来提示调用者,提高可读性.
# 4. 闭包处理错误的模式
- 每当函数返回时,我们应该检查是否有错误发生:但是这会导致重复乏味的代码.
- 基于
defer/panic/recover机制和闭包,得到一个更加优雅的模式。但此模式只有当所有函数都是同一种签名时可用.
// 拥有同样签名的 web 应用处理函数 | |
func handler1(w http.ResponseWriter, r *http.Request) {...} | |
// 假设函数签名相同 | |
func f(a type1, b type2) | |
// 给函数类型一个别名 | |
fType1 = func f(a type1, b type2) | |
/* | |
* 此模式中使用两个帮助函数 | |
* 1) check: 检查是否有错误和 panic 发生的函数 | |
* 2) errorhandler: 包装函数,接收 fTYpe1 类型函数 fn 返回调用 fn 的函数 | |
*/ | |
func check(err error) {if err!= nil {panic(err)}} | |
func errorHandler(fn fType1) fType1 { | |
return func(a type1, b type2) { | |
defer func() { | |
if err, ok := recover().(error); ok { | |
log.Printf("run time panic: %v",err) | |
} | |
}() | |
} | |
} |
- 错误发生时会
recover并打印在日志中;除了简单打印,应用也可以用template包为用户生成自定义输出,check()函数会在所有的被调用函数中调用 - 通过此机制,所有的错误都会被 recover, 并且调用函数后的错误检查代码也被简化为调用 check (err).
- 此模式下,不同的错误处理必须对应不同的函数类型;(错误处理) 可能被隐藏在错误处理包内部。可选择更加通用的方式:用一个空接口类型的切片作为参数和返回值.
func f1(a typr1, b type2){ | |
f, _, err := //call function/method | |
check(err) | |
t, err := //call function/method | |
check(err) | |
_, err := //call function/method | |
check(err2) | |
} |
# 5. 启动外部命令和程序
- os 包的 StartProcess 函数可以调用或启动外部系统命令和二进制可执行文件;
/* | |
* name: 执行的进程名 argv: 传递参数或选项 attr 含有系统环境基本信息的结构体 | |
* 返回值:被启动进程的 Id (Pid) | |
*/ | |
func StartProcess(name string, argv []string, attr *ProcAttr) (*Process, error) |
exec包有同样功能的更简单的结构体和函数;主要是exec.Command(name String, arg ...string)和Run()- 首先需要用系统命令或可执行文件的名字创建一个
Command对象 - 然后使用 Command 对象作为接收者调用
Run()
- 首先需要用系统命令或可执行文件的名字创建一个
# 6. Go 中的单元测试和基准测试
- 所有的包都应该有一定的必要文档,然后同样重要的是对包的测试
- Go 中有名为
testing的包被专门用来进行自动化测试,日志和错误报告。并且还包含一些基准测试函数的功能. gotest是Unix bash脚本,在Windows下需要配置MINGW环境;在Windows环境下把所有的pkg/linux_admin64替换成pkg/windows.- 对一个包 (单元) 测试,需要写一些可以频繁 (每次更新后) 执行的小块测试单元来检查代码的正确性。所以必须写一些 Go 源文件来测试代码。测试程序必须属于被测试的包,并且文件名满足
*_test.go的格式,所以测试代码和包中的业务代码是分开的. _test程序不会被普通的 Go 编译器编译,所以当放应用部署到生产环境时它们不回被部署;只有gotest会编译所有的程序:普通程序和测试程序.- 测试文件中必须导入
"testing"包,且包含一些名称以TestXxx开头的全局函数,例如: TestFmtInterface.
/* | |
* 测试函数必须有这种形式的头部: | |
* T 是传给测试函数的结构类型,用来管理测试状态,支持格式化测试日志 如: t.Log,t.Error | |
* 在函数结尾把输出和想要的结果对比,如果不等就打印一个 UC 哦呜。成功则直接返回 | |
*/ | |
func TestFunc(t *testing.T) |
通知测试失败的函数
| 方法签名 | 作用 |
|---|---|
| func (t *T) Fail() | 标记测试函数失败,继续执行剩下测试 |
| func (t *T) FailNow() | 标记测试函数失败,终止运行,同文件其他测试略过,执行下个文件 |
| func (t *T) Log(args ...interface{}) | args 被默认的格式格式化并打印到错误日志中 |
| func (t *T) Fatal(args ...interface{}) | 先执行 Log 再执行 Fatal 的效果 |
testing包中有一些类型和函数可以用来做加单的基准测试;- 测试代码中必须包含以
BenchmarkZzz打头的函数,并接收一个*testing.B类型的函数 - 命令 go test -test.beanch=.* 会运行所有的基准测试函数;
- 代码中的函数会被调用 N 次,并展示 N 的值和函数执行的平均时间,单位
ns(纳秒). - 如果使用 testing.Benchmark 调用,直接运行程序即可
- 测试代码中必须包含以
func BeanchmarkReverse(b *testing.B) { | |
... | |
} |
# 7. 性能调试 (分析并优化 Go 程序)
- 时间和内存消耗
- 在 Unix 命令中使用
xtime goprogexe, 此处的 progexec 是一个 Go 可执行程序, - 输出类似 56.63u 0.26s 56.92r 1642640kB progexec, 分别对应 用户时间,系统时间,实际时间和最大内存占用
- 在 Unix 命令中使用
## 使用便捷脚本 xtime 来测量 | |
#!/bin/sh | |
/usr/bin/time -f '%Uu %Ss %er %MKB %C' "$@" |
- go test 调试
- 如果代码使用了 Go 中
testing包的基准测试功能,可以用gotest标准的-cpuprofile和-memprofile标志向指定文件写入 CPU 或 内存使用情况报告. - 使用方式:
go test -x -v -cpuprofile=prof.out -file x-test.go - 编译执行
x_test.go中的测试,并向prof.out文件中写入 cpu 性能分析信息.
- 如果代码使用了 Go 中
- pprof 调试
- 可以在单机程序
progexec中引入runtime/pprof包; pprof包 以可视化工具需要的格式写入运行时的报告数据.- Go flag 库用来解析命令行,如果命令行设置 cpuprofile flag, 则开始 CPU 性能分析并把结果重定向到对应文件
- 分析程序在程序退出之前调用
StopCPUProfile来刷新挂起的写操作到文件中;用defer保证main返回时触发 - 使用 flag 运行程序:
progexec -cpuprofile=progexec.prof - 然后使用
gopprof progexec progexec.prof
- 可以在单机程序
var cpuprofile = flag.String("cpuprofile", "", "write cpu profile to file") | |
func main() { | |
flag.Parse() | |
if *cpuprofile != "" { | |
f, err := os.Create(*cpuprofile) | |
if err != nil { | |
log.Fatal(err) | |
} | |
pprof.StartCPUProfile(f) | |
defer pprof.StopCPUProfile() | |
} |
- gopprof 命令
- 程序是 Google pprofC++ 分析器的轻微变种
- 开启 CPU 性能分析,GO 程序会以约每秒 100 次的频率阻塞并记录当前执行的
goroutine栈上的程序计数器样本.
1)、 topN
- 用来展示分析结果中最前面的 N 份样本,例如: top5 会展示在程序运行期间调用最频繁的 5 个函数
// 输出结果第五列表示函数的调用频度 | |
Total: 3099 samples | |
626 20.2% 20.2% 626 20.2% scanblock | |
309 10.0% 30.2% 2839 91.6% main.FindLoops | |
... |
2)、 web 或 web函数名
- 该命令生成一份
SVG格式的分析数据图标,并在浏览器中打开 - 还有一个 gv 命令可以生成
PostScript格式的数据,并在GhostView中打开,此命令需要安装graphviz - 函数被表示成不同的矩形 (被调用越多,矩形越大), 箭头表示函数调用链.
3)、 list 函数名 或 weblist 函数名
- 展示对应函数名的代码行列表,第二列表示当前执行消耗的时间,可以很好地展示出运行中消耗最大的代码
- 如果发现函数 runtime.mallocgc (分配内存并执行周期性的垃圾回收) 调用频繁,就应该进行内存分析,找出垃圾回收频繁执行的原因和内存大量分配的根源
- 用
-memprofile flag运行这个程序: progexec -memprofile=progexec.mprof - 然后可以再次使用 gopprof 工具: gopprof progexec progexec.mprof
top5,list函数名 等命令同样适用,只不过变成以 MB 为单位测量内存分配的情况.
- 用
// 为了达到上述效果需要上合适的地方添加如下代码 | |
var memprofile = flag.String("memprofile", "", "write memory profile to this file") | |
... | |
CallToFunctionWhichAllocatesLotsOfMemory() | |
if *memprofile != "" { | |
f, err := os.Create(*memprofile) | |
if err != nil { | |
log.Fatal(err) | |
} | |
pprof.WriteHeapProfile(f) | |
f.Close() | |
return | |
} | |
// TOP 5 | |
Total: 118.3 MB | |
66.1 55.8% 55.8% 103.7 87.7% main.FindLoops | |
30.5 25.8% 81.6% 30.5 25.8% main.*LSG·NewLoop | |
... |
- 报告内存分配计数的有趣工具:
gopprof --inuse_objects progexec progexec.mprof |
- web 应用有标准的 HTTP 接口可以分析数据。在 HTTP 服务中添加
import _ "http/pprof" - 为 /debug/pprof/ 下的一些 URL 安装处理器。然后用一个唯一的参数 -- 服务中的数据分析的 URL 来执行
gopprof命令
import _ "http/pprof" | |
gopprof http://localhost:6060/debug/pporf/profile # 30-second CPU profile | |
gopprof http://localhost:6060/debug/pporf/heap # heap profile |
# 6. 协程与通道
协程 (goroutine) 与 通道 (channel)
Go 作为 21 世纪语言,Go 原生支持应用之间的同学 (网络,客户端和服务端,分布式计算) 和程序的并发.
程序可以在不同的处理器和计算机上同时执行不同的代码段.
Go 语言为构建并发程序的基本代码块是 协程 (goroutine) 与 通道 (channel).
需要语言,编译器和 runtime 的支持,Co 语言提供的垃圾回收器对并发变成只管重要
不要通过共享内存来通信,而通过通信来共享内存 通信强制协作
# 1. 并发,并行和协程
协程的定义
- 一个应用程序是运行在机器上的一个进程;进程是一个运行在自己内存地址空间的独立执行体。一个进程由一个或多个操作系统线程组成,这些线程其实是共享同一个内存地址空间的一起工作的执行体.
- 几乎所有 ' 正式 ' 的程序都是多线程的,已便让用户或计算机不必等待,或者能够同时服务多个请求 (如 web 服务器), 或增加性能和吞吐量 (通过对不同的数据集并行执行代码)
- 一个并发程序可以在一个处理器或者内核上使用多个线程来执行任务,但只有同一个程序在某个时间点同时运行在多个或者多处理器上才是真正的并行.
- 并行是一种通过使用多处理器以提高速度的能力。所以并发程序可以是并行也可以不是.
- 公认多线程的应用难以做到转却,最主要的问题是内存中的数据共享,数据会被多线程以无法预知的方式进行操作,导致一些无法重现或随机的结果 (竞态) 不要使用全局变量或共享内存,它们会使代码在并发运算的时候产生危险
- 并发解决之道在于同步不同的线程,对数据加锁就可以保证同时只有一个线程可以变更数据。加锁会带来更高的复杂度,更容易使代码出错以及更低的性能,所以这个方法不再适合现代多核心 / 多处理器编程:
thread-per-connection模型不够有效 - Go 的标准库
sync中有一些工具用来在低级别代码中实现加锁; - Go 更倾向于其他的方式,诸多合适的范式中:
Communicating Sequential Processes (顺序通信处理)(CSP, C.Hoare 发明)message passing-model (消息传递)(已经运用在其它语言中,如 Erlang)
- Go 中的应用程序并发处理的部分被称作
grouting (协程), 可以更有效的并发运算.- 在协程和操作系统线程之间并无一对一的关系:协程是根据一个或多个线程的可用性,映射 (多路复用) 在其之上
- 协程调度器在 Go 运行时很好的完成了这个工作.
- 协程工作在相同的地址空间中,所以共享内存的方式一定是同步的;可以使用
sync包实现,但不建议,Go 使用channel1来同步协程 - 当系统调用 (如:等待 I/O) 阻塞协程时,其它协程会继续在其它线程上工作。协程的设计隐藏了许多线程创建和管理方面的复杂工作.
- 协程是轻量的,比线程更轻.(使用少量的内存和资源): 使用 4K 的栈内存就可以在堆中创建.
- 协程创建非常廉价,必要的时候可以轻松创建并运行大量协程,并且协程对栈进行了分割,从而动态的增加 (或缩减) 内存的使用;栈的管理是自动的,但不是由垃圾回收器管理,而是在协程退出后自动释放
- 协程可以运行在多个操作系统之间,也可以运行在线程之类,以很小的占用就可以处理大量任务。操作系统线程上的协程时间片,可以使用少量的操作系统线程就能拥有任意多个提供服务的线程,且 Go 运行时可以自主意识到哪些协程被阻塞,暂时搁置它们并处理其他线程
- 两种并发方式:确定性的 (明确定义排序) 和 非确定性的 (加锁 / 互斥从而未定义排序).Go 的协程和通道支持确定的并发方式 (通道具有
sender和receiver) - 协程是通过使用关键字 go 调用 (执行) 一个函数或方法来实现的 (也可以是匿名或
lambda函数). 这样会在当前的计算过程中开始一个同时进行的函数,在相同的地址空间中且分配了独立的栈,例如:go sum(bigArray), 在后台计算总和. - 协程的栈会根据需要进行伸缩,不出现栈溢出;开发者不需要关系栈的大小。当协程结束的时候,它会静默退出:用来启动这个程序的函数不会得到任何返回值.
- 任何 Go 程序都必须有的
main()函数也可以看做一个协程,尽管它没有通过go来启动。协程可以在程序初始化的过程中运行 (在init()函数中). - 在一个协程中,如果需要进行非常密集的运算,可以在运算循环中周期的使用
runtime.Gosched(): 让出处理器,允许运行其他协程;它并不会使当前协程挂起,所以它会自动恢复执行。使用Gosched()可以使计算均匀分布
并发和并行的差异
- Go 的并发原语提供了良好的并发设计基础:表达程序结构以便表示独立地执行的动作
- Go 的重点不在于并行的首要位置:并发程序可能是并行的,也可能不是。并行是一种通过使用多处理器以提高速度的能力。一个设计良好的并发程序在并行方面的表现也非常出色.
- Go 默认没有并行指令,只有一个独立的核心或处理器被专门用于 Go 程序,不论它启动了多少个协程;所以这些协程是并发运行的,但是不是并行运行的:同一时间只有一个协程会处在运行状态
- 使用
GOMAXPROCS变量,使程序可以使用多个核心运行,此时协程就是真正的并行运行 - 只有 gc 编译器真正实现了协程,适当的吧协程映射到操作系统线程。使用
gccgo编译器,为每一个协程创建操作系统线程
GOMAXPROCS 启动多核执行
- 在 gc 编译器下必须设置
GOMAXPROCS为一个大于默认值 1 的数值来允许运行时支持使用多于 1 个的操作系统线程,所有的协程都会共享同一个线程,除非将GOMAXPROCS设置为一个大于 1 的数。当GOMAXPROCS大于 1 时,会有一个线程池管理许多的线程。通过gccgo 编译器GOMAXPROCS有效的与运行中的协程数量相等. - 如果环境变量 GOMAXPROCS>= n 机器核心数量,或执行
runtime.COMAXPROCS(n), 协程会被分散到 n 个处理器上。更多的处理器并不意味着性能的线性提升。通常 n 个核心的情况下设置GOMAXPROCS 为 n-1获得最佳性能,但同样需要遵守 协程数量 > 1 + GOMAXPROCS >1 - 某一时间只有一个协程在执行,不要设置
GOMAXPROCS - GOMAXPROCS 等同于 (并发的) 线程数量,在一台核心数大于 1 的机器上,会竟可能有等同于核心数的线程在并行运行
用命令指定使用的核心数量
- 使用
flags包 - 协程可以通过调用
runtime.Goexit()来停止
var numCores = flag.Int("n", 2, "number of CPU cores to use") | |
// 在 main 中调用 | |
flag.Parse() | |
runtime.GOMAXPROCS(*numCores) |
main()函数返回时,程序退出:不会等待任何非 main () 协程的结束.- 服务器程序中,每个请求都会启动一个协程来处理,
server()函数必须保持运行状态。通常使用无限循环. - 协程是独立的处理单元,一旦陆续启动一些协程,无法确定其真正开始执行时间,所以代码逻辑必须独立于协程的调用顺序
- 协程案例:在一个非常长的数组中查找一个元素。将数组分割为若干个不重复的切片,启用多个并行的协程进行查找
Go 协程 (goroutines) 和协程 (coroutines)
- 其他语言中的协程概念与 Go 语言有些相似,但是不同
- Go 协程意味着并行 (或者可以以并行的方式部署), 协程一般不是如此
- Go 协程通过通道来通信;协程通过让出和恢复操作来通信
- Go 协程比协程更强大,也更容易从协程的逻辑复用到 Go 协程.
# 2. 协程间的信道
概念
- 协程必须通信才会变得更有用:彼此之间发送和接收信息必须协调 / 同步它们的工作.
- 协程可以使用共享变量来通信,但是很不提倡,因为这种方式给所有的共享内存的多线程都带来了困难
- Go 有一种特殊的类型,通道 (channel), 就像一个可以用于发送类型化数据的管道,由其负责协程之间通信,从而避开所有共享内存导致的陷阱
- Go 通过过道进行通信保证了同步性。数据在通道中进行传递:
- 在任何给定时间,一个数据被设计为只有一个协程可对其访问,所以不会发生数据竞争.
- 数据的所有权 (可以读写数据的能力) 也因此被传递.
- 通道服务与通信的两个:值的交换,同步的保证了两个计算 (协程) 任何时候都是可知状态.

- 通道声明:
var identifier chan datatype, 未初始化的通道值是 nil. - 通道只能传输一种类型的数据:例如:
chan int或者chan string, 所有类型都可以用于通道,空接口interface{}也可以。甚至可以创建通道的通道. - 通道实际上是类型化消息的队列:使数据得以传输。是先进先出 (FIFO) 的结构,所以可以保证发送元素的顺序.
- 通道可以比作 Unix shells 中的双向管道 (two-way pipe), 通道也是引用类型,使用
make()函数分配内存. - 通道是第一类对象:可以存储在变量中,作为函数的参数传递,从函数返回以及通过通道发送自身.
- 通道是类型化的,允许类型检查,比如尝试使用整数通道发送一个指针.
var ch1 chan string | |
ch1 = make(chan string) | |
// 简短赋值 | |
ch1 := make(chan string) | |
chanOfChans := make(chan int) //int 通道的通道 | |
funcChan := make(chan func()) // 函数通道 |
通信操作符 <-
- <- 操作符直观的标示了数据的传输:信息按照箭头的方向流动.
ch <- int1表示:用通道 ch 发送变量 int1 (双目运算符,中缀 = 发送)
- 从通道流出 (接收), 三种方式:
int2 = <- ch表示:变量 int2 从通道 ch (一元运算符的前缀操作符,前缀 = 接收) 接收数据,int2 没有被声明可写成:int2 := <-ch<- ch可以单独调用获取通道的 (下一个) 值,当前值会被丢弃,但是可以用来验证
if <- ch != 1000 { | |
... | |
} |
- 同一个操作符 <- 既用于发送也用于接收,但 Go 会根据操作对象自主区分。虽然非强制要求,但是为了可读性通道的命令通常以
ch开头或者包含chan. 通道的发送和接收都是原子操作:彼此总是互不干扰的.
func main() { | |
ch := make(chan string) | |
go sendData(ch) | |
go getData(ch) | |
time.Sleep(1e9) | |
} | |
func sendData(ch chan string) { | |
ch <- "Washington" | |
ch <- "Tripoli" | |
ch <- "London" | |
ch <- "Beijing" | |
ch <- "Tokyo" | |
} | |
func getData(ch chan string) { | |
var input string | |
// time.Sleep(2e9) | |
for { | |
input = <-ch | |
fmt.Printf("%s ", input) | |
} | |
} |
main()函数中启动了两个协程:sendData()通过通道 ch 发送了 5 个字符串,getData()按顺序接收并打印- 如果两个协程需要通信,必须给定同一个通道作为参数才行.
- 运行时 (runtime) 会检查所有的协程是否在等待 (可从某个通道读取或写入某个通道), 意味着程序将无法继续执行,这是死锁 (deadlock) 的一种形式,运行时 (runtime) 可以检测这种情况
- 注意事项:不要使用打印状态来表明通道的发送和接收顺序:打印状态和通道实际发生读写的时间延迟会导致和真实顺序不同
通道阻塞
- 默认情况下,通信是同步且无缓冲的:
- 在有接收者接收数据之前,发送不会结束.
- 一个无缓冲的通道在没有空间来保存数据的时候:
- 必须有一个接收者准备好接收通道的数据然后发送者可以直接把数据发送给接收者.
- 所有通道的发送 / 接收操作在对方准备好之前是阻塞的:
- 对于同一个通道,发送操作 (协程或函数中), 在接收者准备好之前是阻塞的:如果 ch 中的数据无人接收,就无法再给通道传入其他数据:新的输入无法在通道非空的情况下传入。所以发送操作会等待 ch 再次变为可用状态:通道值被接收时 (可以传入变量)
- 对于同一个通道,接收操作是阻塞的 (协程或函数中), 直到发送者可用:如果通道中没有数据,接收者就阻塞了.
- 一个协程在无限循环中给通道发送整数数据。但因为没有接收者,只输出了一个数字 0
pump()函数为通道提供数值,也被称为生产者
func main() { | |
ch1 := make(chan int) | |
go pump(ch1) //pump hangs | |
fmt.Println(<-ch1) // prints only 0 | |
} | |
func pump(ch chan int) { | |
for i := 0; ;i++ { | |
ch <-i | |
} | |
} | |
输出: 0 |
通过一个 (或多个) 通道交换数据进行协程同步
- 通信是一种同步形式:通过通道,两个协程在 通信 (协程会和) 中某刻同步交换数据。无缓冲工具成为了多个协程同步的完美工具.
- 甚至可以在通道两端互相阻塞对方,形成死锁状态.Go 运行时会检查并
panic, 停止程序. - 无缓冲通道会被阻塞。设计无阻塞的程序可以避免这种情况,或者使用带缓冲的通道.
同步通道 -- 使用带缓冲的通道
- 一个无缓冲通道只能包含一个元素,有时显得很局限。可以在扩展
make命令中设置其容量
//buf 是通道可以同时容纳的元素 (此处是 string) 个数 | |
buf := 100 | |
ch1 := make(chan string,buf) |
- 在缓冲满载 (缓冲被全部使用) 之前,给一个带缓冲的通道发送 或 读取数据不会被阻塞,直到缓冲满载.
- 缓冲容量和类型无关,可以给通道设置不同的容量,只要拥有相同元素类型。内置
cap函数可以返回缓冲区的容量 - 如果容量大于 0, 通道就是异步的:缓冲满载 (发送) 或变空 (接收) 之前通信不回阻塞,元素会按照发送顺序被接收.
- 如果容量为 0 或未设置,通信仅在收发双方准备好的情况下才可以成功.
- 使用通道的缓冲,程序会在 "请求" 激增的时候表现更好:更具弹性,专业术语:更具伸缩弹性
- 在设计算法时首先考虑无缓冲通道,只有在不确定的情况下使用缓冲.
同步: ch :=make (chan typr,value)
value == 0 -> synchronous, unbuffered(阻塞)value > 0 -> asynchronous, buffered(非阻塞) 取决于 value 元素
协程中用通道输出结果
- 为了知晓计算何时完成,可以通道通信回报。在例子
go sum(bigArray)中 - 也可以使用通道来达到同步目的,此方法被称为 信号量 (semaphore). < 通道通过发送信号告知处理完成 >
- 在其他协程运行时让 main 程序无限阻塞的常规做法是在 main 函数的最后放置一个
select{}
ch := make(chan int) | |
go sum(bigArray, ch) // bigArray puts the calculated sum on ch | |
// ...do something else for a while | |
sum := <- ch // wait for, and retrieve the sum |
信号量模式
并行实现的 for 循环
- for 循环并行计算迭代可能带来很好的性能提升,不过所有的迭代都必须是独立完成.
for i, v := range data { | |
go func (i int,v float64) { | |
doSomething(i, v) | |
... | |
}(i, v) | |
} |
缓冲通道实现信号量
- 型号量是实现互斥锁 (排外锁) 常见的同步机制,限制对资源的访问,解决读写问题,比如没有实现信号量的
sync的 Go 包,使用带缓冲的通道可以轻松实现:- 带缓冲通道的容量和要同步的资源容量相同
- 通道的长度 (当前存放的元素个数) 与当前资源被使用的数量相同
- 容量减去通道的长度就是未处理资源的个数 (标准信号量的整数值)
/* | |
* 不论通道中存放的是什么,只关注长度; | |
* 英雌创建一个长度可变但容量为 0 的 (字节) 通道: | |
*/ | |
type Empty interface {} | |
type semaphore chan Empty | |
/* | |
* 以可用资源的数量 N 来初始化信号量 | |
* semaphore : sem = make (semaphore, N) | |
* 然后直接对信号量进行操作 | |
* acquire n resources | |
*/ | |
func (s semaphore) P(n int) { | |
e := new(Empty) | |
for i := 0; i < n; i++ { | |
s <- e | |
} | |
} | |
// release n resources | |
func (s semaphore) V(n int) { | |
for i:= 0; i < n; i++{ | |
<- s | |
} | |
} | |
/* 实现互斥的案例 */ | |
/* mutexes */ | |
func (s semaphore) Lock() { | |
s.P(1) | |
} | |
func (s semaphore) Unlock(){ | |
s.V(1) | |
} | |
/* signal-wait */ | |
func (s semaphore) Wait(n int) { | |
s.P(n) | |
} | |
func (s semaphore) Signal() { | |
s.V(1) | |
} |
给通道使用 for 循环
for循环的 range 语句可以用在通道ch上,从通道获取值- 从指定通道读取数据直到通道关闭,才继续执行下方代码.
- 另一个协程必须写入
ch(不然代码就阻塞在 for 循环了), 而且必须在写入完成后才关闭.
for v := rang ch { | |
fmt.Printf("The Value is %v\n",v) | |
} |
- 习惯用法:通道迭代模式
- 生产者 - 消费者模式:
- 通常,需要从包含了地址索引字段
Items的容器给通道填入元素。为容器的类型定义一个方法Iter(), 返回一个只读的通道 Items
- 通常,需要从包含了地址索引字段
- 生产者 - 消费者模式:
func (c *container) Iter() <- chan item { | |
ch := make(chan item) | |
go func() { | |
for i := 0;i < c.Len(); i++ { //or use a for-range loop | |
ch <- c.items[i] | |
} | |
} () | |
return ch | |
} |
- 在协程里,一个 for 循环迭代容器 c 中的元素 (对于树或图的算法,简单的 for 循环可以替换为深度优先搜索)
- 其运行在自己启动的协程中,所以上边的迭代用到了一个通道和两个协程 (可能运行在不同的线程上).
- 如果在程序结束前,向通道写值的协程未完成工作,则这个协程不会被垃圾回收;
- 这是设计使然,这种并不符合预期的行为正式由通道这种线程安全的通信方式所导致的.
- 因此,一个协程可能为了写入一个永远无人读取的通道而被挂起成为一个 bug, 并不会被悄悄回收
// 调用此方法的代码可以如下迭代容器: | |
for x := range container.Iter() {...} |
习惯用法:生产者消费者模式
Produce() 函数 产生 Consume 函数需要的值.
两者可以运行在独立的协程中,生产者在通道中放入消费者读取的值。整个过程可替换为无限循环
for { | |
Consume(Produce()) | |
} |
通道的方向
通道类型可以用注解表示 只发送 或 只接收
- 只接收的通道 (<- chan T) 无法关闭,关闭通道是发送者用来表示不再给通道发送值,所以对只接受通道没有意义
- 通道创建的时候都是双向的,但也可以分配有方向的通道变量
var send_only chan <- int // channel can only receive data | |
var recv_only <- chan int // channel can only send data | |
// 分配有方向的通道 | |
var c = make(chan int) // bidirectional | |
go source(c) | |
go sink(c) | |
func source(ch chan<- int){ | |
for { ch <- 1 } | |
} | |
func sink(ch <-chan int) { | |
for { <-ch } | |
} |
习惯用法:管道和选择器模式
协程处理从通道接收的数据并发送给输出通道:
- 通过方向注解来限制协程对通道的操作
sendChan := make(chan int) | |
receiveChan := make(chan string) | |
go processChannel(sendChan, receiveChan) | |
func processChannel(in <-chan int, out chan<- string) { | |
for inValue := range in { | |
result := ... /// processing inValue | |
out <- result | |
} | |
} |
- 使用选择器 (' 筛 ') 作为算法,答应输出的素数,每个 prime 都有一个选择器,如下图:

- 协程 filter(in,out chan int,prime int) 拷贝整数到输出通道,丢弃可以被 prime 整除的数字,然后每个 prime 又开启一个新的协程,生成器和选择器并发请求
package main | |
import "fmt" | |
// 向 channel 通道发送 2,3,4 ... 序列 | |
func generate(ch chan int) { | |
for i := 2; ; i++ { | |
ch <- i // Send 'i' to channel 'ch'. | |
} | |
} | |
// 从 in 通道复制数据到 out 通道 | |
// 去除能被 prime 整除的数 | |
func filter(in, out chan int, prime int) { | |
for { | |
i := <-in // 从 in 通道中 接收新的 value 赋予 i | |
if i%prime != 0 { | |
out <- i // 将 i 发送到 out 通道 | |
} | |
} | |
} | |
// 筛选通道序列中的素数 | |
func main() { | |
ch := make(chan int) // 创建一个新的通道 | |
go generate(ch) // 以协程的方式启动 generate (). | |
for { | |
prime := <-ch | |
fmt.Print(prime, " ") | |
ch1 := make(chan int) | |
go filter(ch, ch1, prime) | |
ch = ch1 | |
} | |
} |
实现方式二:
- 工厂函数
sieve,generate和filter; 创建通道并返回,使用协程的lambda函数. main函数短小清晰:调用sieve()返回包含素数的通道
package main | |
import ( | |
"fmt" | |
) | |
// Send the sequence 2, 3, 4, ... to returned channel | |
func generate() chan int { | |
ch := make(chan int) | |
go func() { | |
for i := 2; ; i++ { | |
ch <- i | |
} | |
}() | |
return ch | |
} | |
// Filter out input values divisible by 'prime', send rest to returned channel | |
func filter(in chan int, prime int) chan int { | |
out := make(chan int) | |
go func() { | |
for { | |
if i := <-in; i%prime != 0 { | |
out <- i | |
} | |
} | |
}() | |
return out | |
} | |
func sieve() chan int { | |
out := make(chan int) | |
go func() { | |
ch := generate() | |
for { | |
prime := <-ch | |
ch = filter(ch, prime) | |
out <- prime | |
} | |
}() | |
return out | |
} | |
func main() { | |
primes := sieve() | |
for { | |
fmt.Println(<-primes) | |
} | |
} |
# 3. 协程的同步:关闭通道 - 测试阻塞的通道
- 通道可以被显示的关闭;尽管与文件不同:
不必每次都关闭. - 只有在当需要告诉接收者不会再提供新值的时候才需要关闭通道.
- 只有发送者需要关闭通道,接收者永远不会需要
通道的关闭
- 在通道的
sendData()完成时发送一个信号,用于getData()检测通道是否关闭或阻塞- 通过函数
close(ch): 将通道标记为无法通过发送操作<-接收更多的值; - 给已经关闭的通道发送或者再次关闭都会导致运行时的
panic. - 在创建一个通道后使用 defer 语句是个不错的办法
- 通过函数
ch := make(chan float64) | |
defer close(ch) |
- 使用 逗号,ok 操作符:用来检测通道是否被关闭.
// 如果 v 接收到值,ok 为 true | |
v, ok := <- ch | |
// 通常和 if 语句一起使用: | |
if v, ok := <-ch; ok { | |
process(v) | |
} | |
// 在 for 循环中接收时,当关闭或者阻塞的时候使用 break: | |
v, ok := <- ch | |
if !ok { | |
break | |
} | |
process(v) |
注意事项
在通道迭代器中,两个协程经常是一个阻塞另一个.
如果程序工作在多核心的机器上,大部分时间只用到了一个处理器。可以通过使用带缓冲的通道来改善.
例如:缓冲大小为 100, 迭代器在阻塞之前,至少可以从容器获得 100 个元素.
如果消费者协程在独立的内核运行,就有可能让协程不会出现阻塞.
容器中元素的数量通常是已知的,需要让通道有足够的容量放置所有的元素.
如此 迭代器就不会阻塞 (尽管消费者协程仍然可能阻塞), 但实际上加倍了迭代容器的内存使用量,
所以通道的容量需要限制一下最大值.
# 4. 使用 select 切换协程
- 从不同并发执行的协程中获取值可以通过关键字
select来完成,和switch控制语句非常相似,也被称作通信开关 select使用轮询机制监听进入通道的数据,也可以是用通道发送值的时候.
select { | |
case u:= <- ch1: | |
... | |
case v:= <- ch2: | |
... | |
default: // 没有准备接收的值 | |
... | |
} |
default语句是可选的;fallthrough行为,和普通的Switch相似,是不允许的.在任何一个
case中执行break或者return, select 就结束了.select 做的就是:选择处理列出的多个通信情况中的一个
如果都阻塞了,会等待其中一个可以处理
如果多个可以处理,随机选择一个
如果没有通道操作可以处理,并且写了
default语句,就会执行default中的内容default永远是可运行的
在
select中使用发送操作并且有default可以确保发送不被阻塞!如果没有default,select就会 一直阻塞,select 语句实现了一种监听模式,通常用在 (无限) 循环中;在某种情况下,通过
break语句使循环退出.
# 5. 通道,超时和计时器 (Ticker)
time 包中有一些有趣的功能可以和通道组合使用.
time.Ticker结构体,这个对象以指定的时间间隔重复的向通道 C 发送时间值:- 时间间隔的单位是 ns (纳秒,int64), 在工厂函数
time.NewTicker中以Duration类型的参数传入:
func NewTicker(dur) *Ticker
type Ticker struct { | |
C <-chan Time // the channel on which the ticks are delivered. | |
// contains filtered or unexported fields | |
... | |
} |
- 在协程周期性的执行一些事情 (打印状态日志,输出,计算等等) 的时候非常有用.
- 调用
Stop()使计时器停止,在defer语句中使用,都很好的适应select语句:
ticker := time.NewTicker(updateInterval) | |
defer ticker.Stop() | |
... | |
select { | |
case u:= <-ch1: | |
... | |
case v:= <-ch2: | |
... | |
case <-ticker.C: | |
logState(status) // call some logging function logState | |
default: // no value ready to be received | |
... | |
} |
time.Tick()函数声明为Tick(d Duration) <- chan Time,当想返回一个通道而不必关闭的时候非常有用:以 d 为周期给返回的通道发送时间,d 是纳秒数.
如果需要如下代码一样,限制处理频率 (
函数 client.Call() 是一个ROC 调用)
这样只会按照指定频率处理请求: chRate 阻塞了更高的频率。每秒处理的频率可以根据机器负载 (和 / 或) 资源的情况变化
import "time" | |
rate_per_sec := 10 | |
var dur Duration = 1e9 / rate_per_sec | |
chRate := time.Tick(dur) // a tick every 1/10th of a second | |
for req := range requests { | |
<- chRate // rate limit our Service.Method RPC calls | |
go client.Call("Service.Method", req, ...) | |
} |
- 定时器 (
Timer) 结构体与 (Ticker) 结构体很像 (NewTimer(d Duration)), 但是它只发送一次时间,在Dration d之后
/** | |
* time.After (d) 函数声明如下: | |
* 在 Duration d 之后,当前时间被发送到返回的通道,与 NewTimer (d).C 等价 类似 Tick () | |
* 但是 After () 只发送一次时间 | |
*/ | |
func After(d Duration) <-chan Time |
- 在
Duration d之后,当前时间被发到返回的通道;所以和NewTimer(d).c是等价的 - 类似
Tick, 但是After()只发送一次时间.
习惯用法:简单超时模式
从通道 ch 中接收数据,但是最多等待 1 秒.
先创建一个信号通道。然后启动一个 lambda 协程,协程在发送数据前是休眠的:
timeout := make(chan bool,1) | |
go func() { | |
time.Sleep(1e9) // 休眠一秒 | |
timeout <- true | |
}() |
然后使用 select 语句接收 ch 或 timeout 的数据:
如果 ch 在 1 秒内没有收到数据,就选择到了 time 分支并放弃了 ch 的读取
select { | |
case <-ch: | |
// 一次从 ch 通道的读取已经发生 | |
case <-timeout: | |
// 从 ch 中读取超时 | |
break | |
} |
第二种形式:取消耗时很长的同步调用
可以使用 time.After() 函数替换 timeout-channel .
在 select 中通过 time.After() 发送超时信号来停止协程的执行.
timeoutNs 纳秒后执行 select 的 timeout 分支,执行 client.Call 的协程也随之结束,不会给通道 ch 返回值
ch := make(chan error,1) | |
go func() {ch <- client.Call("Service.Method",args,&reply)}() | |
select { | |
case resp := <- ch | |
// 使用接收值并回复 | |
case <- time.After(timeoutNs): | |
// call time out | |
break | |
} |
缓冲区大小设置为 1, 避免协程死锁以及确保超时的通道可以被垃圾回收
有多个 case 符合条件时,select 对 case 的选择是伪随机的,在代码中稍作修改
则 select 语句可能不会在定时器超时信号到来时立刻选中 time.After(timeoutNs) 对应的 case
因此协程可能不会严格按照定时器设置的时间结束
ch := make(chan int,1) | |
go func() {for {ch <- 1} }() | |
L: | |
for{ | |
select { | |
case <-ch: | |
... | |
case <-time.After(timeoutNs): | |
// call timed out | |
break L | |
} | |
} |
第三种形式:程序从多个复制的数据库中同时读取。只需要一个答案,需要接收首先到达的答案
Query 函数获取数据库的连接切片并请求。并行请求每一个数据库并返回收到的第一个响应:
func Query(conns []Conn, query string) Result { | |
ch := make(chan Result, 1) | |
for _, conn := range conns { | |
go func(c Conn) { | |
select { | |
case ch <- c.DoQuery(query): | |
default: | |
} | |
}(conn) | |
} | |
return <- ch | |
} |
结果通道 ch 必须是带缓冲的:
保证第一个发送进来的数据有地方可以存放,确保放入的首个数据总会成功
第一个到达的值会被获取而与执行的顺序无关。正在执行的协程总是可以使用 runtime.Goexit() 来停止.
在应用中缓存数据:
应用程序中用到了来自数据库 (或者常见的数据存储) 的数据时,经常会将数据缓存到内存中,
从数据库中获取数据的操作代价很高;如果数据库中的值不发生变化就没有问题.
如果值有变化,则需要一个周期性的从数据库重新读取这些值,缓存值就 (过期) 了
# 6. 协程和恢复 (recover)
用到 recover 的程序,停掉服务器内部的一个失败协程而不影响其他协程的工作.
func server(workChan <-chan *Work) { | |
for work := range workChan { | |
go safelyDo(work) // 启动一个工作协程 | |
} | |
} | |
func safelyDo(work *Work) { | |
defer func() { | |
if err := recover(); err != nil { | |
log.Printf("Work failed with %s in %v",err,work) | |
} | |
}() | |
do(work) | |
} |
如果
do(work)发生 panic, 错误会被记录且协程会推出并释放而其他协程不受影响.recover总是返回nil, 除非直接在 defer 修饰的函数中调用defer 修饰的代码可以调用自身可以使用 panic 和 recover 避免失败的库例程 (库函数)
案例
safelyDo()中 defer 修饰的函数可能在调用 recover 之前就调用了一个 logging 函数,panicking状态不回影响logging代码的运行。因为加入了恢复模式- 函数
do(以及其调用的任何东西) 可以通过调用panic来摆脱不好的情况 - 但是恢复在
panicking的协程内部的:不能被另一个协程恢复
# 7. 任务和 worker (新旧模型对比)
- 当需要处理很多任务;一个 worker 处理一项任务。任务可以被定义为一个结构体
type Task struct { | |
// some state | |
} |
- 旧模式:使用内存共享进行同步
- 由各个任务组成的任务池共享内存;为同步各个 worker 以及避免资源竞争,需要对任务池进行加锁保护:
- sync.Mutex (互斥锁): 用来在代码中保护临界区资源,
- 同一时间只有一个 go 协程 (goroutine) 可以进入该临界区.
- 如果出现同一时间多个 go 协程进入该临界区,则会产生竞争: Pool 结构就无法保证被正确更新
type Pool struct { | |
Mu sync.Mutex | |
Tasks []*Task | |
} |
- 传统模式中的 Worker 代码
- 这些 worker 有许多可以保证并发执行,其可以在 go 协程中启动.
- 一个 worker 先将 pool 锁定,从 pool 获取第一项任务,再解锁和处理任务.
- 加锁保证了同一时间只有一个 go 协程可以进入 pool 中:一项任务有且只能被赋予一个 worker
- 如果不加锁,则工作协程可能会在
task := pool.Tasls[0]发生切换, - 导致
pool.Tasks=pool.Tasks[1:]结果异常,及一些 worker 获取不到任务,而一些任务可能被多个 worker 得到. - 加锁实现同步的方式在工作协程比较少时可以工作的很好,但是工作协程数量大,任务很多时,处理效率将会因为频繁的加锁 / 解锁开销而降低.
- 当工作协程数增加到一个阈值时,程序效率会急剧下降,这就成为了瓶颈
func Worker(pool *Pool) { | |
for { | |
pool.Mu.Lock() | |
// begin critical section: | |
task := pool.Tasks[0] //take the first task 执行第一个任务 | |
pool.Tasks = pool.Tasks[1:] //update the pool of tasks 更新池中的任务 | |
// end critical section | |
pool.Mu.Unlock() | |
process(task) | |
} | |
} |
- 新模式:使用通道
- 使用通道进行同步:使用一个通道接收需要处理的任务,一个通道接收处理完成的任务 (及其结果)
- worker 在协程中启动,其数量 N 应该根据任务数量进行调整.
主线程扮演着 Master节点角色 ,可写成如下形式:
- 这里并不使用锁:从通道得到新任务的过程中没有任何竞争.
- 随着任务数量增加,worker 数量也相应增加,同时性能不回像第一种方式那样下降明显.
- 在 pending 通道中存在一份任务的拷贝,第一个 worker 从 pending 通道中获取第一个任务并进行处理
- 这里并不存在竞争 (对一个通道读取数据和写数据的整个过程是原子性的)
- 某一个任务在哪一个 worker 中执行是不可知的,worker 数量的增多也会增加通信的开销,这会对性能有轻微影响
func main() { | |
pending, done := make(chan *Task), make(chan *Task) | |
go sendWork(pending) // put task with work on the channel | |
for i := 0; i < N; i++ { // start N goroutines to do work | |
go Worker(pending, done) | |
} | |
consumeWork(done) // continue with the processed tasks | |
} | |
//worker 的逻辑:从 pending 通道拿任务,处理后将其放到 done 通道中 | |
func Worker(in,ouyt chan *Task) { | |
for { | |
t := <-in | |
process(t) | |
out <- t | |
} | |
} |
对于任何可以建模为 Master-Worker 范例的问题:
- 一个类似于 worker 使用通道进行通信和交互,Master 进行整体协调的方案都能完美解决.
- 如果系统部署在多台机器上,各个机器上执行 Worker 协程,Master 和 Worker 之间使用 netchan 或者 RPC 进行通信
通道和锁的应用场景 :
- 使用锁的情景:
- 访问共享数据结构中的缓存信息
- 保存应用程序上下文和状态信息数据
- 使用通道的场景:
- 与异步操作的结果进行交互
- 分发任务
- 传递数据所有权
# 8. 惰性生成器的实现
生成器是指被调用时返回一个序列中下一个值的函数,例如:
generateInterger() => 0 | |
generateInterger() => 1 | |
generateInterger() => 2 | |
... |
生成器每次返回的是序列中下一个值而非整个序列;这种特性也被称之为惰性求值:
- 只在需要时进行求值,同时保留相关变量资源 (内存和 CPU), 是一项在需要时对表达式进行求值的技术
- 生成一个无限数量的偶数序列:要产生这样一个序列并且一个个的使用可能会很困难,而且内存会溢出,但是含有通道的 go 协程的函数能轻易实现这个需求.
var resume chan int | |
func integers() chan int { | |
yield := make(chan int) | |
count := 0 | |
go func() { | |
for { | |
yield <- count | |
count++ | |
} | |
}() | |
return yield | |
} | |
func generateInteger() int { | |
return <-resume | |
} | |
func main() { | |
resume = integers() | |
fmt.Println(generateInteger()) //=> 0 | |
fmt.Println(generateInteger()) //=> 1 | |
fmt.Println(generateInteger()) //=> 2 | |
} |
- 从通道读取的值可能会是稍早产生的,并不是在程序被调用时生成的。如果确实需要这样的行为,就需要实现一个请求响应机制.
- 当生成器生成数据的过程是计算密集型且各个结果的顺序并不重要时,可以将生成器放入到 go 协程实现并行化
- 使用大量的 go 协程的开销可能会超过带来的性能增益
使用原则 :
- 通过巧妙地使用空接口,闭包和高阶函数,实现一个通用的惰性生产器的工厂函数
BuildLazyEvakuator - 工厂函数需要一个函数和初始状态作为输入参数,返回一个无参,返回值是生成序列的函数
- 传入的函数需要计算出下一个返回值以及下一个状态参数.
- 在工厂函数中创建一个通道和无限循环的 go 协程,返回值被放入该通道中,返回函数稍后被调用时从该通道中取得该返回值。每当取得一个值时,下一个值即被计算.
# 9. 实现 Futuress 模式
Futures 模式:
- 有时候需要在某一个值之前先对其进行计算.
- 可以在另一个处理器上进行该值的计算,到使用时,该值就已经计算完毕了
Futures 模式通过闭包和通道可以很容易实现,类似于生成器,不同地方在于 Futures 需要返回一个值.
参考案例:
- 假设有一个矩阵类型,需要计算两个矩阵 A 和 B 乘积的逆
- 首先通过函数
Inverse(M)分别对其进行求逆运算,再将结果相乘
func InverseProduct(a Matrix, b Matrix) { | |
a_inv := Inverse(a) | |
b_inv := Inverse(b) | |
return Product(a_inv, b_inv) | |
} |
- a 和 b 的求逆矩阵需要先被计算.
- 调用
Product函数只需要等到a_inv和b_inv的计算完成
func InverseProduct(a Matrix, b Matrix) { | |
a_inv_future := InverseFuture(a) // 启动一个协程 | |
b_inv_future := InverseFuture(b) | |
a_inv := <- a_inv_future | |
b_inv := <- b_inv_future | |
return Product(a_inv, b_inv) | |
} |
InverseFuture函数以goroutine的形式起了一个闭包,该闭包会将矩阵求逆结果放入到 future 通道中:
func IncerseFuture(a Matrix) chan Matrix { | |
future := make(chan Matrix) | |
go func() { | |
future <- Inverse(a) | |
}() | |
return future | |
} |
小结
- 当开发一个计算密集型库时,Futures 模式设计 API 接口是很有意义的.
- 在包中使用 Futures 模式,且能保持友好的 API 接口
- Futures 可以通过一个异步的 API 暴露出来。可以以最小的成本将包中的并行计算移动到用户代码中
# 10. 复用
客户端 / 服务器 (C/S) 模式
客户端 - 服务器应用是
goroutines和channels的亮点所在.客户端 (Client) 可以是运行在任意设备上的任意程序,会按需求请求 (request) 至服务器
服务器 (Server) 接收到请求后开始响应的工作,然后将响应 (response) 返回给客户端
一般是多个客户端 (即多个请求) 对应一个 (或少量) 服务器
使用 Go 的服务器通常会在协程中执行向客户端的响应,故而会对每一个客户端请求启动一个协程.
一个常用的操作方法是客户端请求自身中包含一个通道,而服务器则向这个通道发送响应.
例: Request 结构,其中内嵌了一个 replyc 通道.
type Request struct { | |
a, b int | |
replyc chan int // reply channel inside the Request | |
} | |
// 更通俗的形式 | |
type Reply struct {...} | |
type Request struct { | |
arg1, arg2, arg3 some_type | |
replyc chan *Reply | |
} |
简单形式:服务器会为每一个请求启动一个协程并在其中执行 run() 函数,此类型会将类型为 binOp 的 op
操作返回的 int 值发送到 replyc 通道.
type binOp func(a, b int) int | |
func run(op binOp, req *Request) { | |
req.replyc <- op(req.a, req.b) | |
} |
server 协程会无限循环以从 chan *Request 接收请求,并且为避免被长时间操作堵塞,将为每一个请求启动
一个协程来做具体的工作:
func server(op binOp, service chan *Request) { | |
for { | |
req := <-service // request arrive here | |
// start goroutine for request: | |
go run(op, req) // 无需等待 op 执行完成 | |
} | |
} |
server 本身以协程的方式在 startServer 函数中启动:
startServer 则会在 main 协程中被调用.
func startServer(op binOp) chan *Request { | |
reChan := make(chan *Request) | |
go server(op, reqChan) | |
return reqChan | |
} |
测试案例: 100 个请求会被发送到服务器,只有全部被送达后才会按照相反的顺序检查响应
(程序仅启动了 100 个协程,然而即使执行 100,000 个协程也能在数秒内完成,Go 协程的轻量)
func main() { | |
adder := startServer(func (a,b int) int {return a + b}) | |
const N = 100 | |
var reqs [N]Request | |
for i := 0; i < N ; i++ { | |
req := &reqs[i] | |
req.a = i | |
req.b = i + N | |
req.replyc = make(chan int) | |
adder <- req // adder is a channel of request | |
} | |
// checks: | |
for i := N - 1; i >= 0; i-- { | |
// doesn't matter what order | |
if <- reqs[i].replyc != N+2*i { | |
fmt.println("fail at", i) | |
} else { | |
fmt.Println("Request", i, "is ok !") | |
} | |
} | |
fmt.Println("done") | |
} | |
// 输出: | |
Request 99 is ok! | |
Request 99 is ok! | |
... | |
Request 99 is ok! | |
Request 99 is ok! | |
done |
卸载 (Teardown) : 通过信号通道关闭服务器
上个版本中 server 在 main 函数返回后并没有完全关闭,而被强制结束了.
改进:提供一个退出通道给 server
func startServer(op binOp) (service chan *Request, quit chan bool) { | |
service = make(chan *Request) | |
quit = make(chan bool) | |
go server(op, service, quit) | |
return service, quit | |
} |
server 函数现在则使用 select 在 service 通道和 quit 通道之间做出选择:
func server(op binOp, service chan *request, quit chan bool) { | |
for { | |
select { | |
case req := <- service: | |
go run(op,req) | |
case <-quit: | |
return | |
} | |
} | |
} |
当 quit 通道接收到 true 值时, server 就会返回并结束.
在 main 函数中做出如下更改:
在 main 函数的结尾处放入: quit <- true
adder, quite := startServer(func (a, b int) int { return a + b }) |
# 11. 限制同时处理的请求数
使用带缓冲区的通道很容易实现这一点,其缓冲区容量就是同时处理请求的最大数量.
超过
MAXREQS的请求将不会被同时处理,当信号通道表示缓冲去已满是handle函数将不会阻塞且不在处理其他请求,直到某个请求从
sem中被溢出.sem就像一个信号量,(程序中表示特定条件的标志量)应用程序可以通过使用缓冲通道 (通道被用作信号量) 使协程同步其对该资源的使用,从而充分利用优先资源
package main | |
const MAXREQS = 50 | |
var sem = make(chan int, MAXREQS) | |
type Request struct { | |
a,b int | |
replyc chan int | |
} | |
func process(r *Request) { | |
// do something | |
} | |
func handle(r *Request) { | |
sem <-1 // doesn't matter what we put in it | |
process(r) | |
<- sem // one empty place in the buffer: the next request can start | |
} | |
func server(service chan *Request) { | |
for { | |
request := <- service | |
go handle(request) | |
} | |
} | |
func main() { | |
service := make(chan *Request) | |
go server(service) | |
} |
# 12. 链式协程
演示案例 :
chaining.go 展示了启动巨量的 Go 协程时多么容易,协程已全部在 main 函数中的 for 循环里启动。当循环完成后,
一个 0 被写入到最右边的通道里,于是 100,000 个协程开始执行,接着所有结果会在 1.5 秒内被打印出来
- 主线程的 right <- 0, right 不是最初循环的那个 right, 而是最终循环的 right
- for 循环中最初的 go f (left,right) 因为没有发送者一直出于等待状态
- 当主线程的 right <- 0 执行时,类似于递归函数在最内层产生返回值一般
package main | |
import ( | |
"flag" | |
"fmt" | |
) | |
var ngoroutine = flag.Int("n", 1000, "how many goroutines") | |
func f(left, right chan int) {left < -1 + <-right} | |
func main() { | |
flag.Parse() | |
leftmost := make(chan int) | |
var left, right chan int = nil, leftmost | |
for i := 0; i < *ngoroutine; i++ { | |
left, right = right, make(chan int) | |
go f(left, right) | |
} | |
right <- 0 // bang! | |
x := <-leftmost // wait for completion | |
fmt.Println(x) // 100000, ongeveer 1,5 s | |
} |
# 13. 在多核心上并行计算
(经典信号量模式) 案例:
运行时需将 GOMAXPROCS 设置为 NCPU
假设有 NCPU 个 CPU 核心: const NCPU = 4 //对应一个四核处理器 ,
目标:将计算量分成 NCPU 个部分,没一个部分都和其他部分并行运行.
DoAll()函数创建了一个sem通道,每个并行计算都将在其发送完成信号,在 for 循环中NCPU个协程被启动了,每个协程会承担
1/NCPU的工作量。每一个DoPart()协程都会向sem通道发送完成信号.DoAll()会在 for 循环中等待NCPU个协程完成:sem通道就像一个信号量,
func DoAll(){ | |
sem := make(chan int, NCPU) // Buffering optional but sensible | |
for i := 0; i < NCPU; i++ { | |
go DoPart(sem) | |
} | |
// Drain the channel sem, waiting for NCPU tasks to complete | |
for i := 0; i < NCPU; i++ { | |
<-sem // wait for one task to complete | |
} | |
// All done. | |
} | |
func DoPart(sem chan int) { | |
// do the part of the computation | |
sem <-1 // signal that this piece is done | |
} | |
func main() { | |
runtime.GOMAXPROCS(NCPU) // runtime.GOMAXPROCS = NCPU | |
DoAll() | |
} |
# 14. 并行化大量数据的计算
使用场景:处理数量巨大且互不相关的数据项,它们从一个 in 通道被传递进来,当处理完成后将其放入 out 通道
处理流程: Prepocess (预处理) / StepA (步骤 A) / StepB (步骤 B) /.../ PostProcess (后处理)
- 一个用于解决按顺序执行每个步骤的顺序流水线算法如下:
- 一次只执行一个步骤,且按照顺序处理,在项目没有被
PostProcess且放入out通道之前不会处理下一个项目
func SerialProcessData(in <-chan *Data,out chan<- *Data) { | |
for data := range in { | |
tempA := PreprocessData(data) | |
tempB := ProcessSetpA(tempA) | |
tempc := ProcessSetpB(tempB) | |
out <- PostProcessData(tmpC) | |
} | |
} |
- 更高效的计算方式:让每一个处理步骤作为一个协程独立工作。每一个步骤从上一步的输出通道中获得输入数据
- 这种方式仅有极少数时间会被浪费,而大部分时间所有步骤都一直在执行中
- 调整通道的缓冲区大小可进一步优化整个过程
func ParallelProcessData (in <-chan *Data, out chan<- *Data) { | |
// make channels: | |
preOut := make(chan *Data, 100) | |
stepAOut := make(chan *Data, 100) | |
stepBOut := make(chan *Data, 100) | |
stepCOut := make(chan *Data, 100) | |
// start parallel computations: | |
go PreprocessData(in, preOut) | |
go ProcessStepA(preOut,StepAOut) | |
go ProcessStepB(StepAOut,StepBOut) | |
go ProcessStepC(StepBOut,StepCOut) | |
go PostProcessData(StepCOut,out) | |
} |
# 15. 漏桶算法
客户端 - 服务器结构:
- 客户端协程执行一个无限循环从某个源头 (也许是网络) 接收数据;数据读取到
Buffer类型的缓冲区.
为避免分配过多的缓冲区以及释放缓冲区,保留一份空闲缓冲区列表,并且使用一个缓冲通道来表示此列表: var freelist = make(chan *Buffer,100)
- 这个可重用的缓冲区队列 (freeList) 与服务器是共享的。当接收数据时,客户端尝试从
freeList
获取缓冲区;如果此时通道为空,则会分配新的缓冲区。一旦消息被加载后,将被发送到服务器的 serverChan
var serverChan = make(chan *Buffer) |
客户端算法代码:
func client() { | |
for { | |
var b *Buffer | |
// Grab a buffer if available; allocate if not | |
select { | |
case b = <- freeList: | |
// Got one; nothing more to do | |
default: | |
// None free, so allocate a new one | |
b = new(buffer) | |
} | |
loadInto(b) // Read next message from the network | |
serverChan <- b // Send to server | |
} | |
} |
服务器循环接收来自客户端的信息并处理,然后尝试将缓冲区返回给共享的空闲缓冲区:
- 此方法在
freeList通道已满时,无法放入空闲freeList通道缓冲区会被抛弃由垃圾收集器回收
func server() { | |
for { | |
b := <-serverChan // wait for work | |
process(b) | |
// Reuse buffer if three's room | |
select { | |
case freeList <- b: | |
// Reuse buffer is free slot on freeList; nothing more to do | |
default: | |
// Free list full, just carry on : the buffer is 'dropped' | |
} | |
} | |
} |
# 16. 使用通道并发访问对象
- 为了保护对象被并发访问修改,可以使用协程在后台顺序执行匿名函数来替代使用同步互斥锁.
- 如下案例中有一个类型
Person其中包含一个字段chF, 这是一个用于存放匿名函数的通道. - 这个结构在构造函数
NewPerson()中初始化的同时会启动一个后台协程backend. backend方法会在一个无限循环中执行chF中放置的所有函数,有效的将其序列化从而提供安全的并发访问- 更改和读取
salary方法会通过将一个匿名函数写入chF通道中,然后backend()按顺序执行
package main | |
import ( | |
"fmt" | |
"strconv" | |
) | |
type Person struct { | |
Name string | |
salary float64 | |
chF chan func() | |
} | |
func NewPerson(name string, salary float64) *Person { | |
p := &Person{name, salary, make(chan func())} | |
go p.backend() | |
return p | |
} | |
func (p *Person) backend() { | |
for f := range p.chF { | |
f() | |
} | |
} | |
// Set salary. | |
func (p *Person) SetSalary(sal float64) { | |
p.chF <- func() { p.salary = sal } | |
} | |
// Retrieve salary. | |
func (p *Person) Salary() float64 { | |
fChan := make(chan float64) | |
p.chF <- func() { fChan <- p.salary } | |
return <-fChan | |
} | |
func (p *Person) String() string { | |
return "Person - name is: " + p.Name + " - salary is: " + strconv.FormatFloat(p.Salary(), 'f', 2, 64) | |
} | |
func main() { | |
bs := NewPerson("Smith Bill", 2500.5) | |
fmt.Println(bs) | |
bs.SetSalary(4000.25) | |
fmt.Println("Salary changed:") | |
fmt.Println(bs) | |
} | |
// 输出 | |
Person - name is: Smith Bill - salary is: 2500.50 | |
Salary changed: | |
Person - name is: Smith Bill - salary is: 4000.25 |